两年前,英特尔酷睿Ultra平台问世促使PC行业迅速步入AI PC时代,同时也掀起了PC行业新一轮创新风潮。然而相较以往的硬件体验与产品形态创新而言,立足于AI技术的创新主要来自于应用侧。不同领域AI应用大量涌现,使得AI在创造力、高效性等方面展现出了无与伦比的优势。
不过在过去一年多的时间里,AI PC行业虽然发展迅速,但始终缺乏一个真正的爆点。而年初DeepSeek国产大语言模型落地,则成为了AI PC爆发的契机。作为一个完全开源和免费的国产推理模型,DeepSeek是真正能够让每个人都实现低成本部署本地AI助手的大语言模型,尤其是使用英特尔酷睿Ultra平台AI PC去做部署的话,不仅可以实现零门槛快速部署,同时借助英特尔酷睿Ultra平台出色的AI算力加持,整体体验更加出色。
此外,月之暗面Kimi推出的160亿参数大模型moonlight-16B-A3B-Instruct也是非常火的一款开源模型。
所以今天我们就来看看如何使用英特尔酷睿Ultra平台AI PC,来快速部署并使用DeepSeek-R1大语言模型和moonlight-16B-A3B-Instruct大语言模型,同时我们也可以看看整体的性能表现到底如何?
·部署平台硬件配置信息
本次我们使用Ollama以及Flowy这两款软件对DeepSeek-R1进行了本地化部署。而moonlight则是通过Miniforge部署。这次使用的硬件平台配置如下:
CPU:英特尔酷睿Ultra 5 225H
GPU:英特尔锐炫130T核显
内存:32GB LPDDR5X
硬盘:1TB PCIe 4.0固态硬盘
系统:Windows 11 24H2(26100.2161)
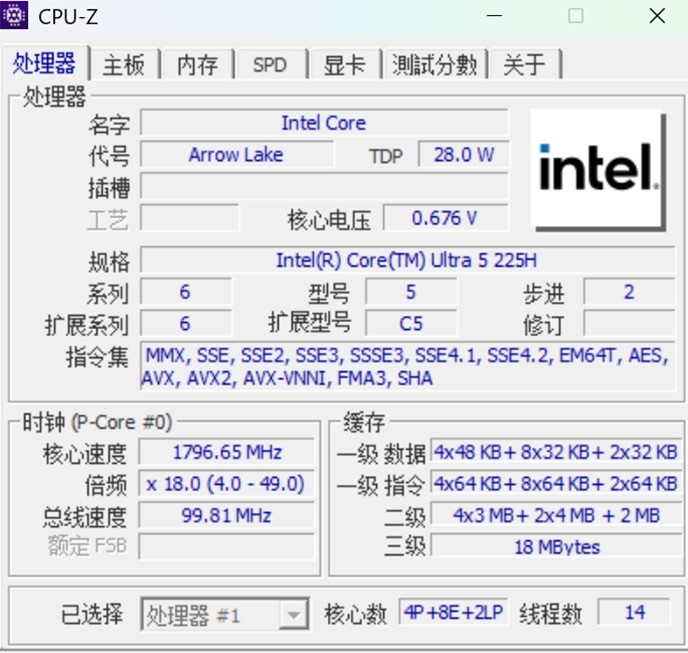
可以看到,从硬件配置来看,使用酷睿Ultra平台AI PC部署DeepSeek-R1的成本并不高,酷睿Ultra 5 225H处理器+锐炫130T核显这样的主流配置即可实现,并不需要一味上高端平台,这对于AI PC向大众用户普及无疑有着深远意义。
接下来,我们看看如何在自己的AI PC上部署一个能够在不联网情况下也能使用的、更加安全、成本更低的“DeepSeek AI助手”,同时也看看锐炫130T核心在运行DeepSeek-R1大模型进行推理时会有怎样的表现?
·借助Ollama或Flowy轻松部署本地AI助手
「预先准备」
在开始部署DeepSeek-R1之前,大家需要先做两个准备:
其一,将英特尔锐炫GPU驱动升至当前最新版本。比如笔者在撰写这篇文章前就将锐炫130T核显的驱动更新到了6559版本。【点击此处进入官网驱动下载页面】
其二,下载Ollama或Flowy软件。选择用哪个软件主要看自己的喜好和习惯。Ollama默认需要通过简单的命令来运行和使用大模型,上手有一点点门槛,但下载、部署模型基本不受限制;而Flowy则直接是可视化软件,安装之后即插即用,只是目前所能部署的大语言模型种类有限。
另外我们可以【直接在魔搭社区或Github下载】针对英特尔酷睿Ultra平台优化过的Ollama。
Flowy软件的下载地址可以【点击此处进入】
「Ollama的安装与部署」
做好准备之后,我们先看看如何用Ollama来将DeepSeek-R1部署到我们自己的AI PC上。
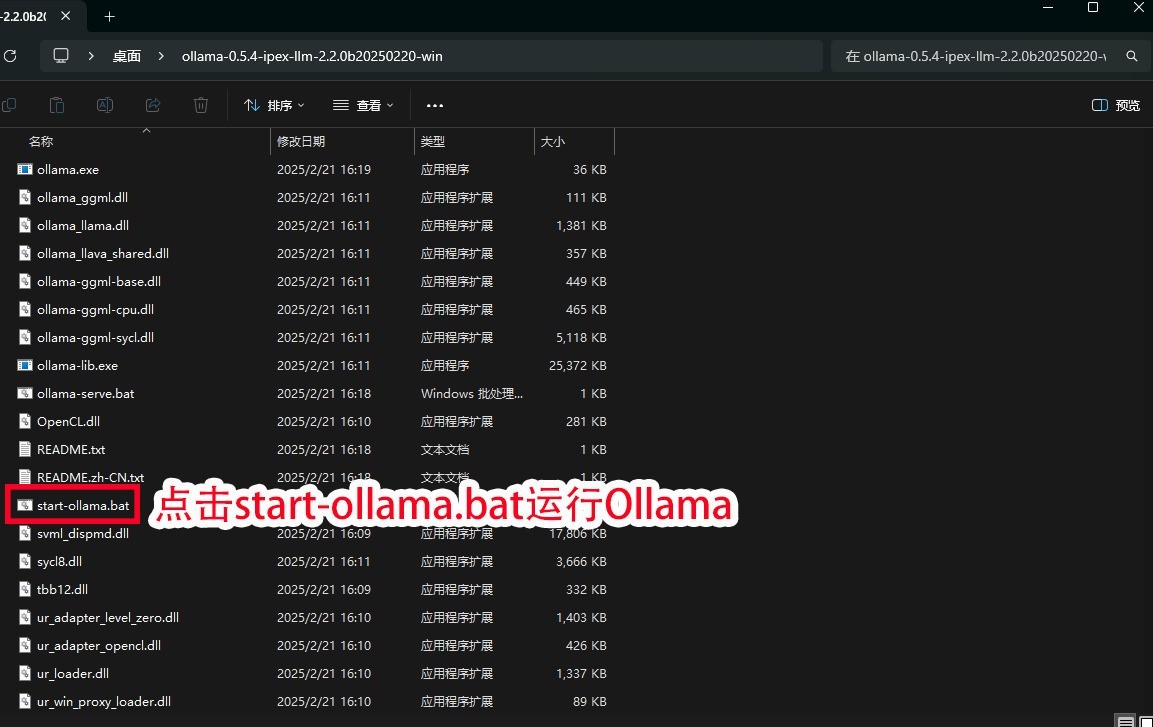
第一步:将下载好的Ollama绿色安装文件解压缩,并拷贝到容量空间更大的硬盘里。之后如下图所示点击start-ollama.bat运行ollama本地服务器。
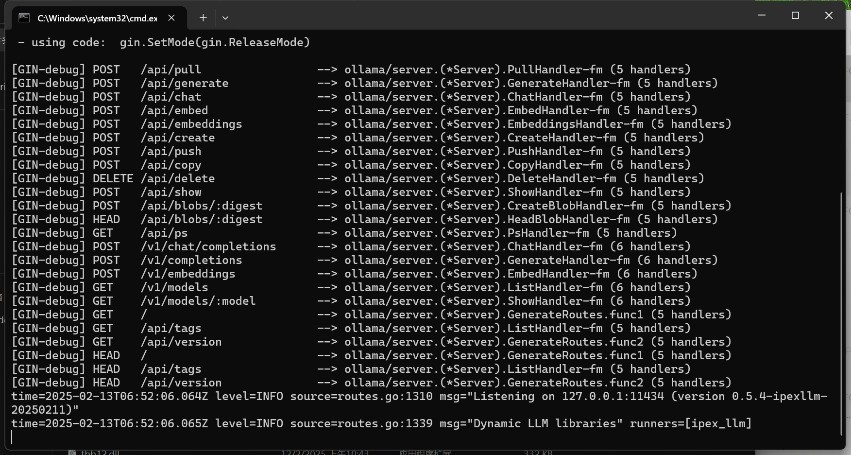
成功运行后会弹出如下图所示的命令行窗口。
第二步:打开「Windows PowerShell」或「终端」或「命令提示符」窗口。直接通过Windows系统搜索即可,这三个习惯用哪个就用哪个。
下面我们以命令提示符窗口为例:
首先通过:
「cd C:\修改为你解压后?件的位置\ollama-ipex-llm-0.5.4-20250211」
这条命令进入ollama文件夹。
笔者直接放在C盘根目录,所以直接输入cd C:\ollama-ipex-llm-0.5.4-20250211即可。
之后通过:
「ollama run deepseek-r1:7b」
这条命令下载并部署deepseek模型。如果想要部署不同规模的DeepSeek-R1,只需要更改冒号后面的数字即可,比如14b、32b等等。
完成上述步骤之后,ollama会自动开始下载并部署大模型,期间无需做任何操作。
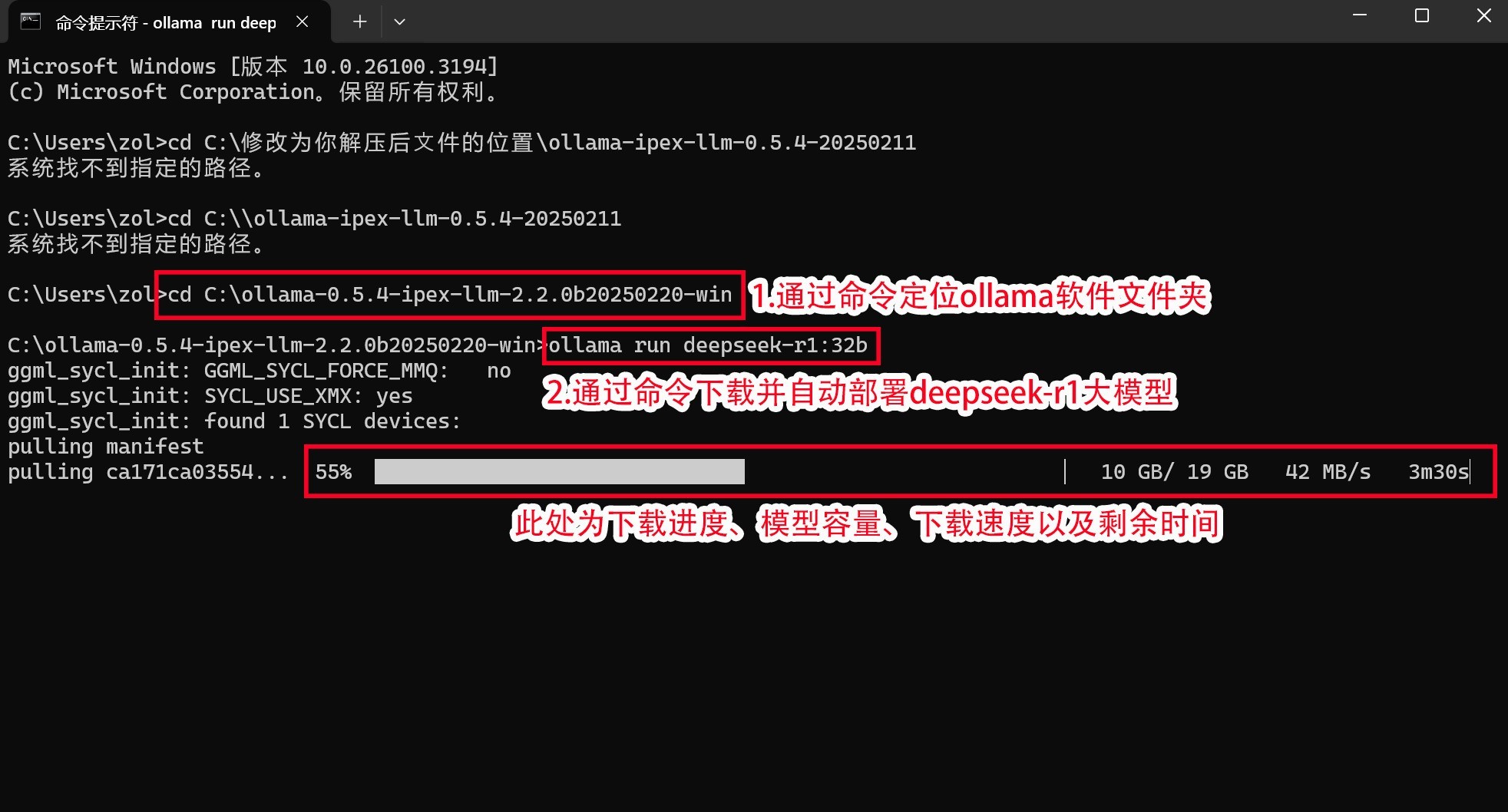
第三步:等待下载完成之后,弹出「Send a massage」之后,用户就可以直接使用刚刚部署好的DeepSeek-R1大模型了。
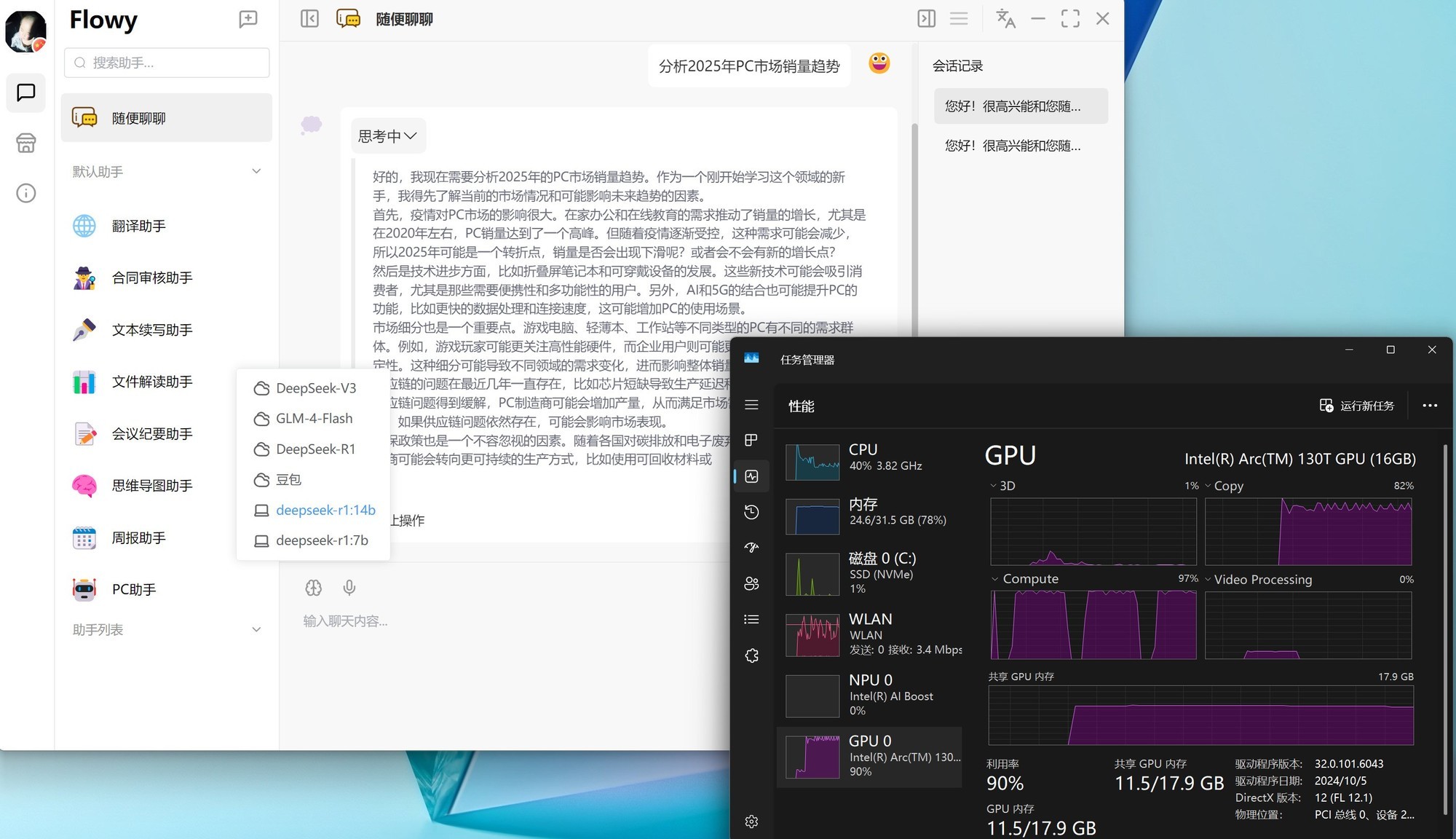
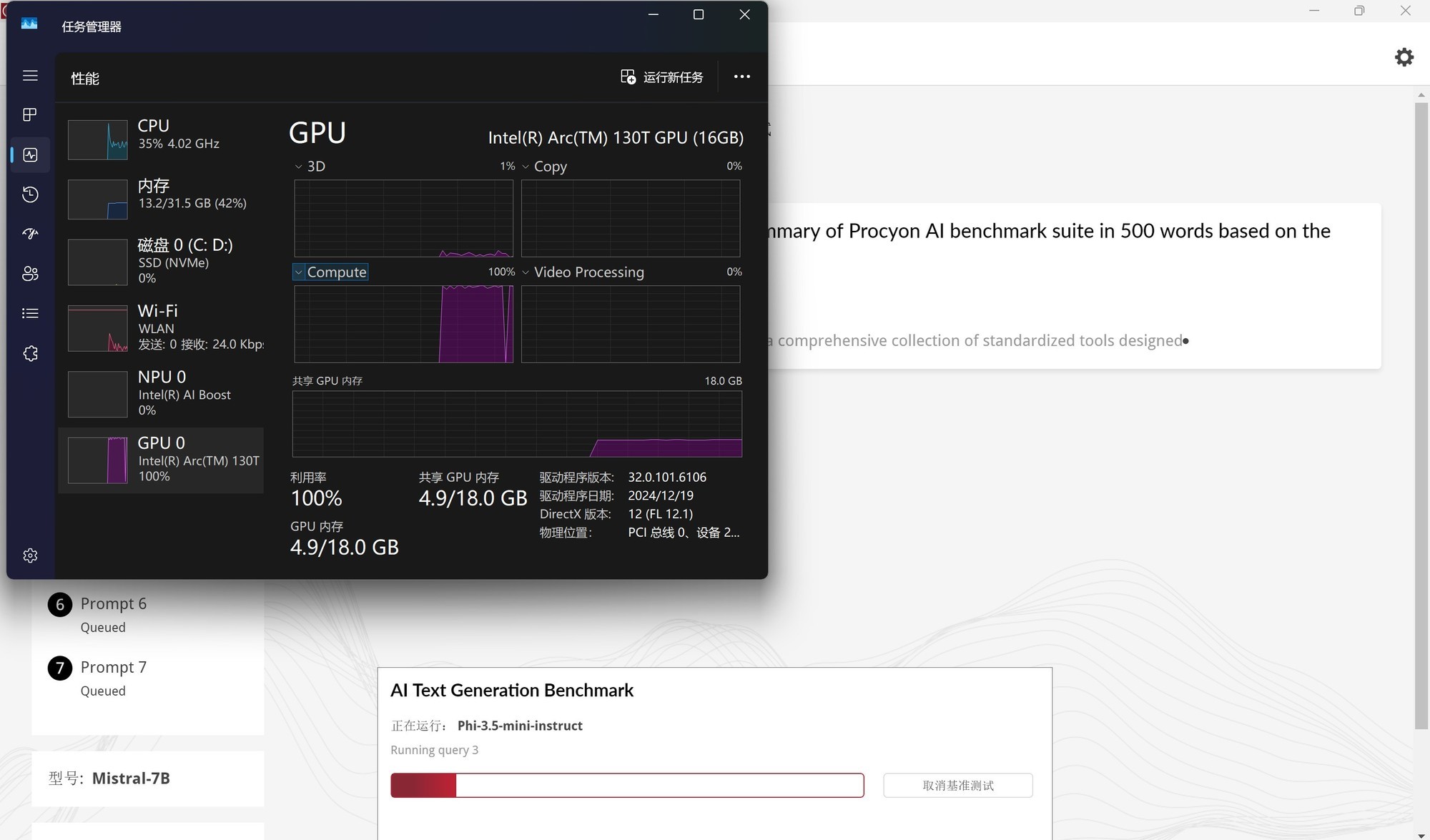
另外大家可以打开任务管理器,看看GPU的Compute是否已经被占满,占满即证明成功在酷睿Ultra AI PC上完成了DeepSeek-R1的部署。
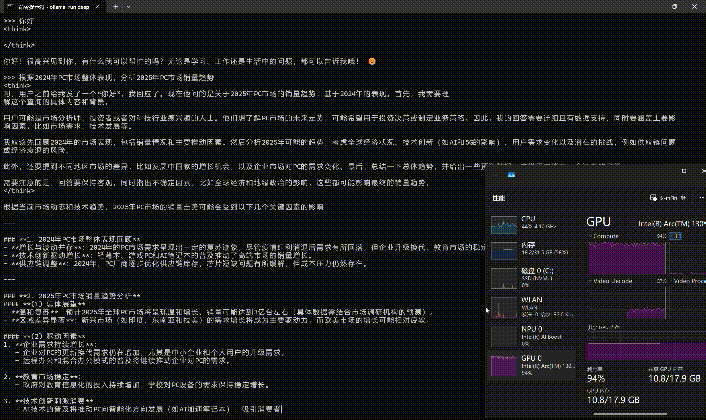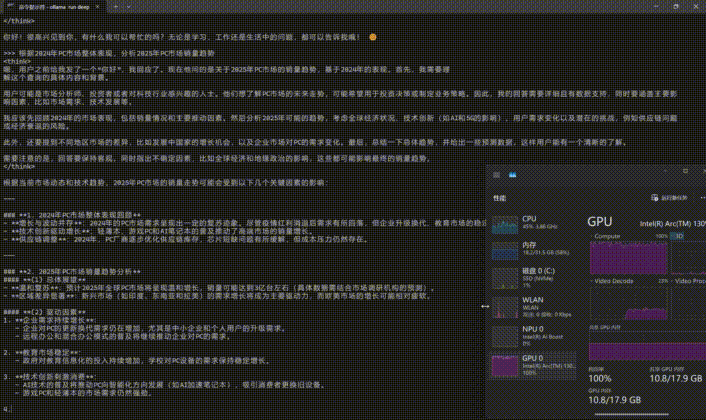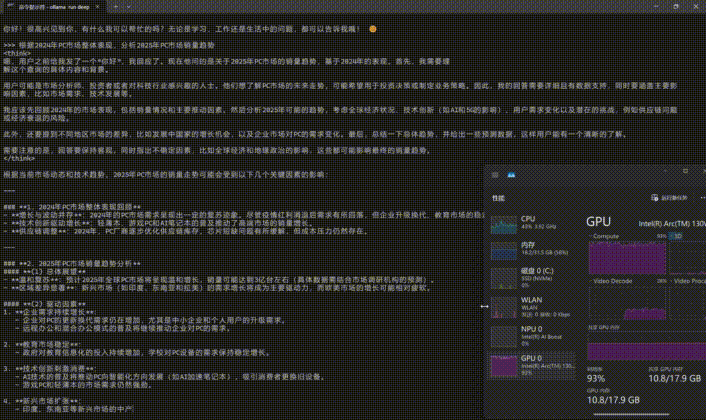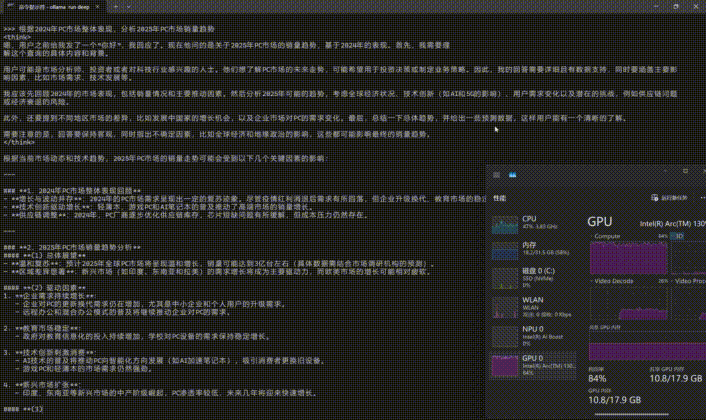
此外,ollama并不是只支持命令式操作,用户可以通过Edge或Chrome浏览器中的「Page Assist」扩展程序打造Web UI界面。也可以下载「Chatbox AI」部署客户端。
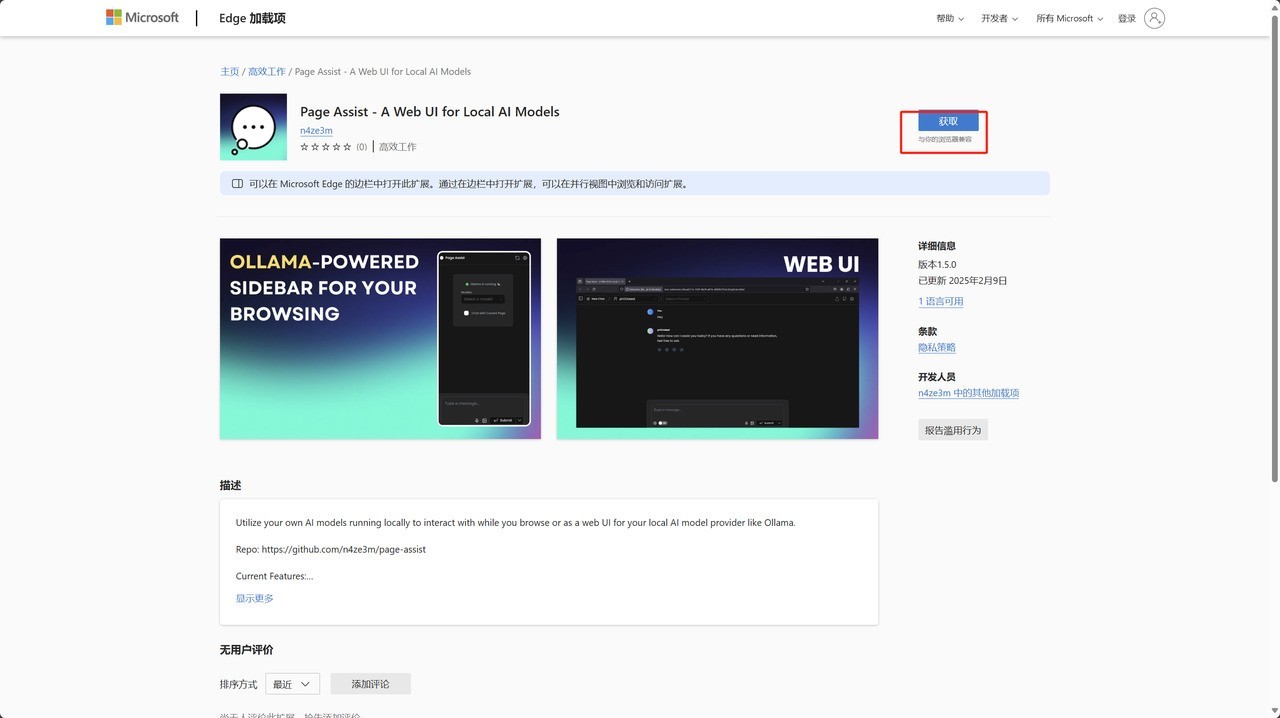
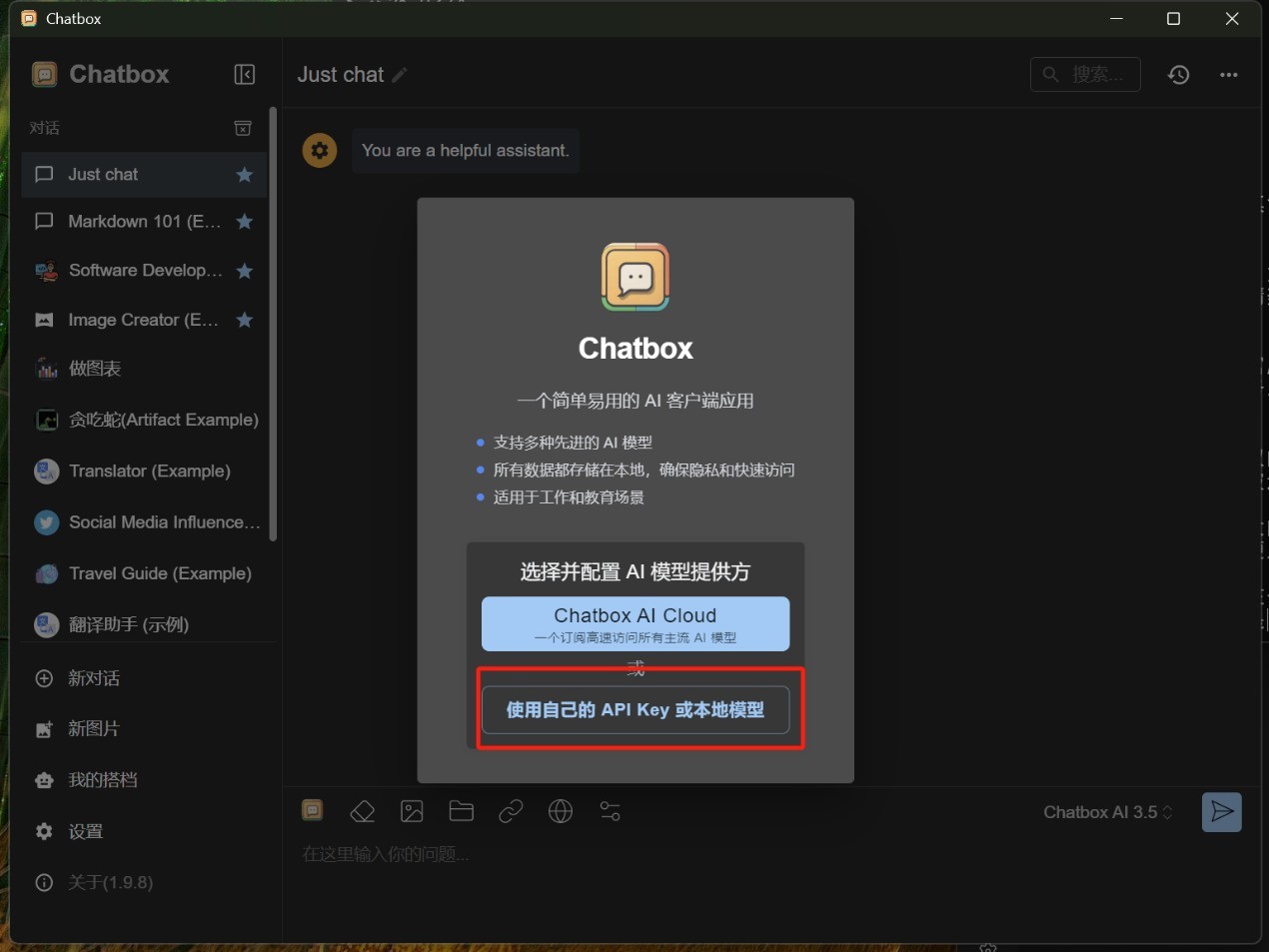
这里简单说一下Chatbox的使用方法,下载安装完成之后,在保持ollama本地服务器运行的状态下,按照下面两张图红框所示进行设置,之后就可以通过Chatbox来使用DeepSeek-R1了。
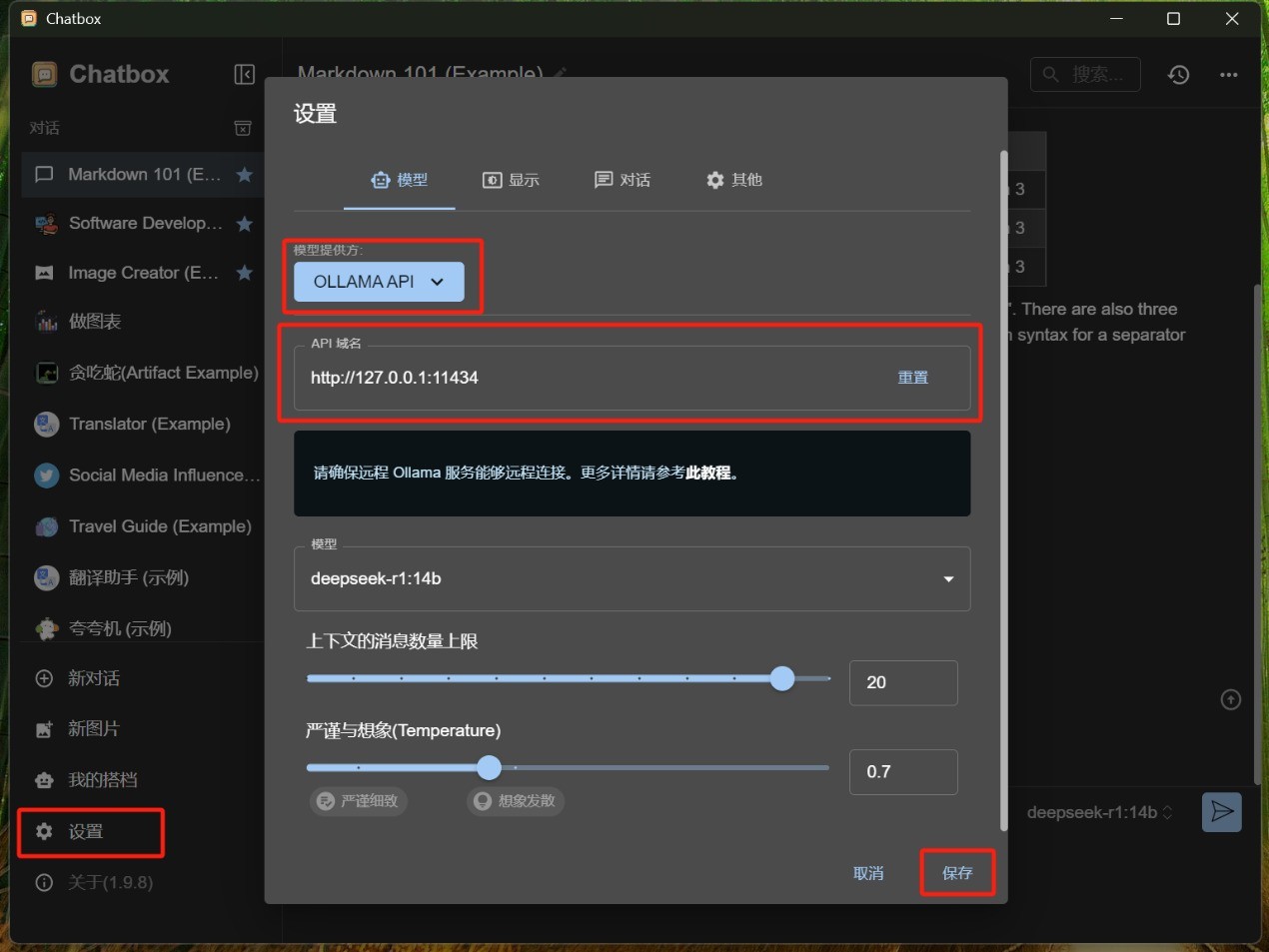
判断是否成功依然是打开任务管理器,查看GPU的Compute占用情况,下图是笔者部署完成之后,使用DeepSeek-R1时GPU Compute被占满,这种状态就证明部署成功。
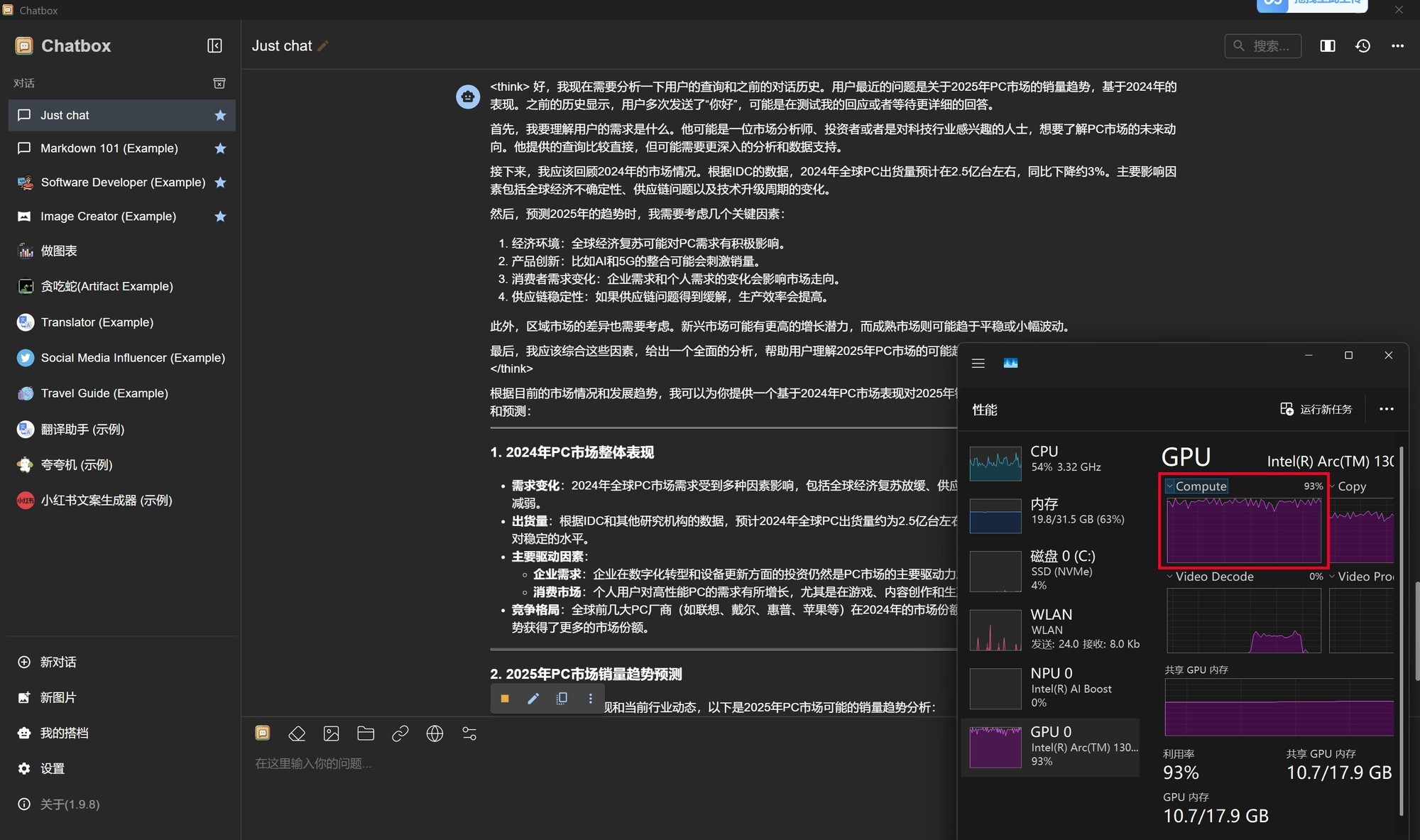
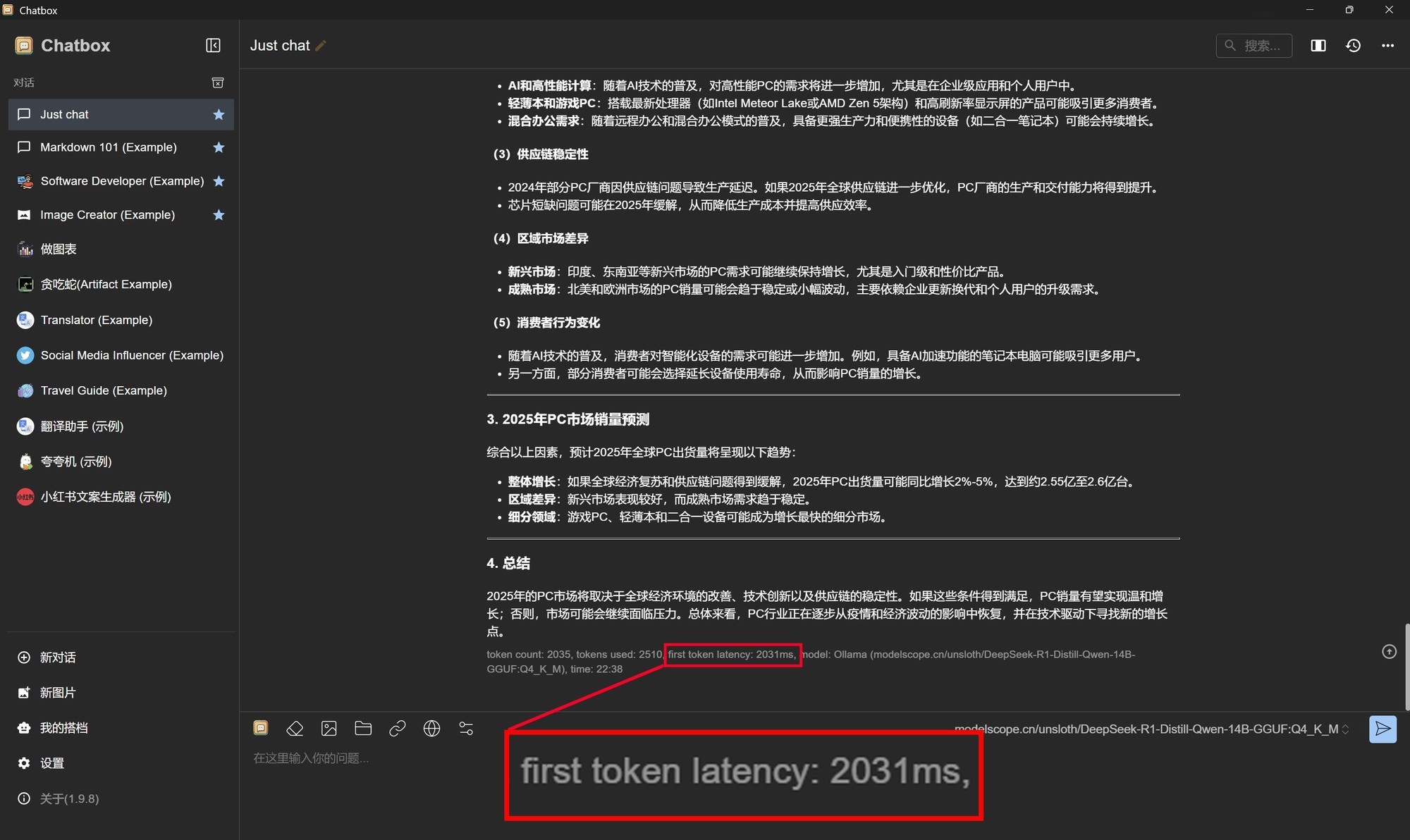
另外我们也查看了14B模型的token生成情况,可以看到首个token生成速度仅为2031毫秒,也就是2秒多一点点,速度非常快。
「Flowy的安装与部署」
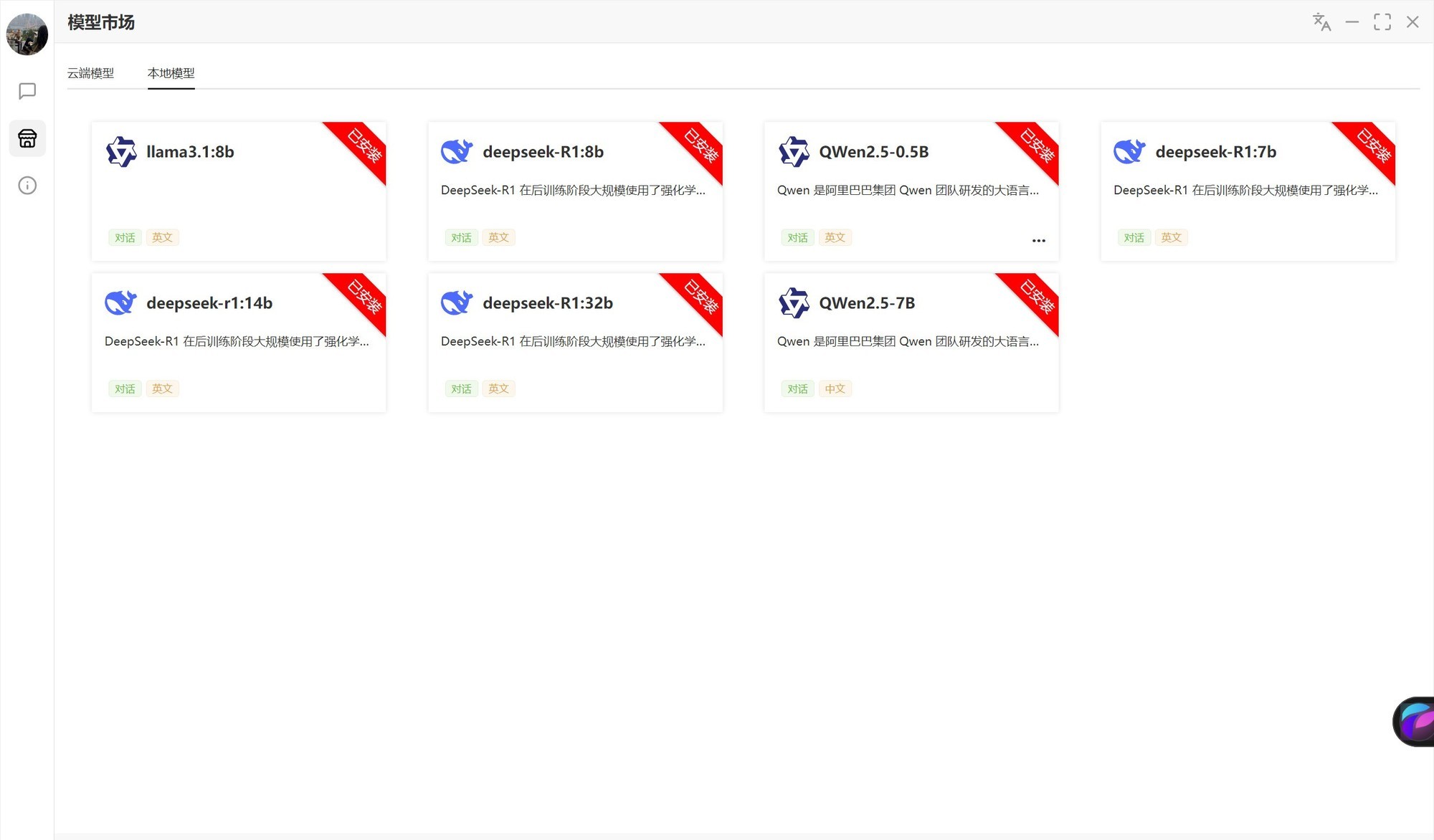
相比Ollama而言,通过Flowy部署DeepSeek-R1就相当简单了。下载安装Flowy之后,打开软件找到本地模型,默认提供了七种常用大语言模型。目前DeepSeek-R1支持7B、8B、14B以及32B四种,直接下载部署即可使用。
Flowy在运行DeepSeek-R1时同样会借助英特尔锐炫GPU来进行推理,Compute也会被占满。借助锐炫GPU出色的AI计算加速能力,虽然会比云端服务的生成速度慢一些,但是胜在断网也能用,而且更加安全、更加私密。
另外笔者对比了DeepSeek-R1:7B和14B的运行速度,下面两幅Gif图都是1倍速录制,第一张图为7B,生成速度更快,但是最终结果呈现的颗粒度不够细腻;第二张图为14B,生成速度慢一些,但是最终结果呈现的更加完整、更富有逻辑性。


·本地部署moonlight-ipex-llm大模型
moonlight-ipex-llm也是非常适合英特尔酷睿Ultra平台使用的本地AI大模型,其后缀的ipex-llm就代表了它是支持英特尔ipex-llm框架的,而且整体部署方式比较简单,无需科学上网。另外moonlight实际上就是之前非常火的月之暗面Kimi推出的160亿参数大模型,本地部署之后就相当于有了一个断网也能用的Kimi AI助手。
在部署之前我们要先准备三个文件:
首先我们需要【点击此处进入Github】,分别点击下图红框里的convert.py和run_moonlight-16b-a3b-instruct.py两个文件,并将代码分别复制到两个记事本中。

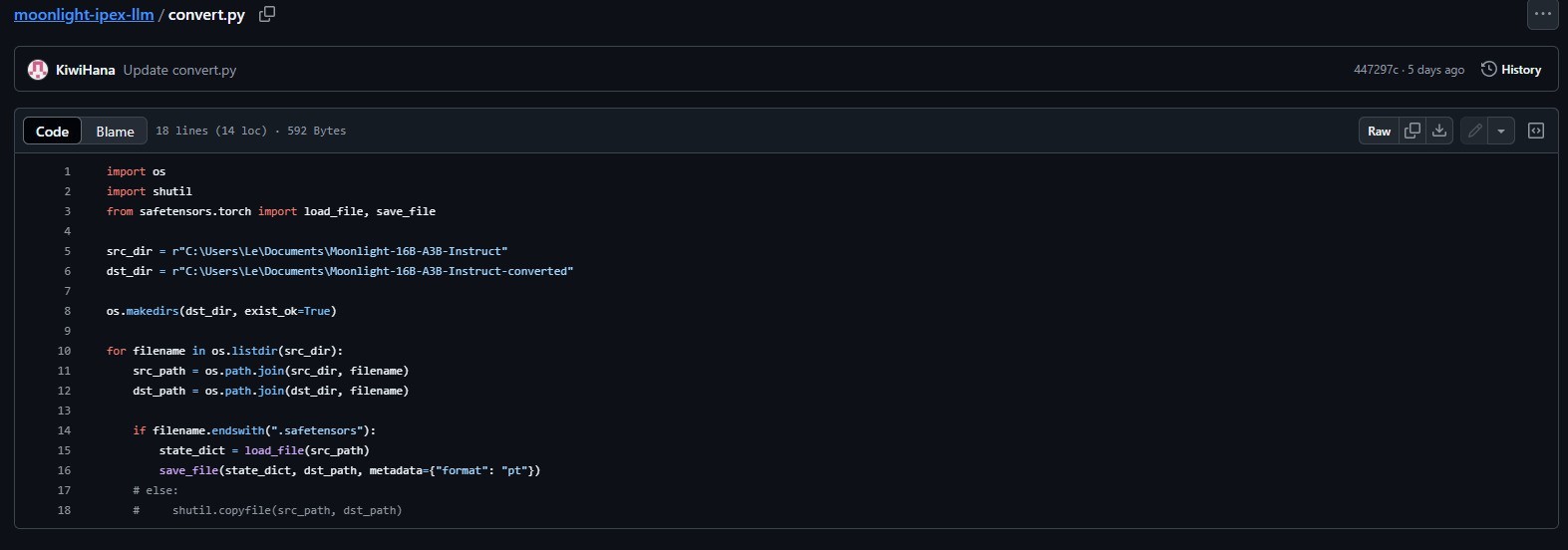
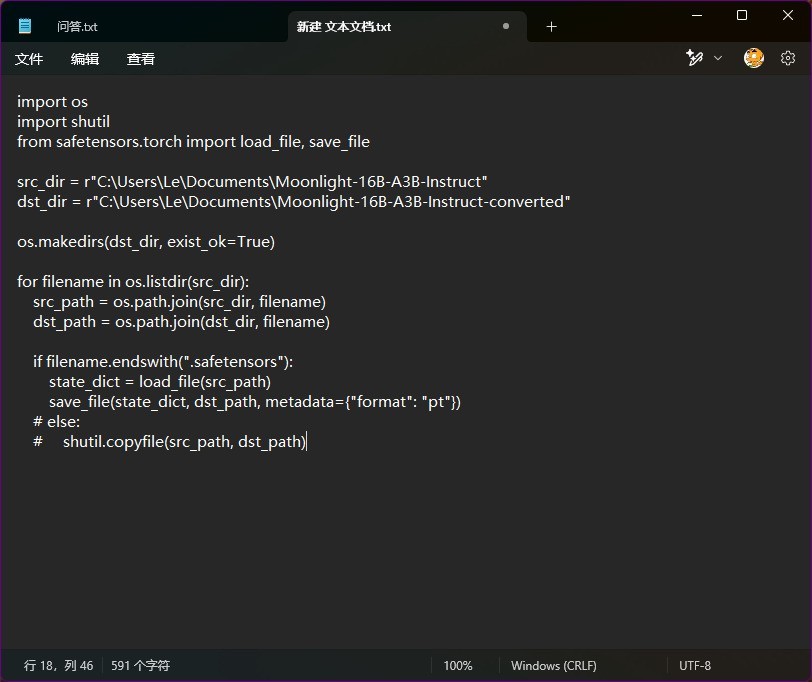
之后保存代码,并将两个记事本的文件命名以及.txt文件扩展名分别改成convert.py和run_moonlight-16b-a3b-instruct.py,如下:
其次,下拉Github页面或【直接点击此处下载miniforge】,这是一款轻量化的Python环境与包管理工具:
这里可以根据自己的系统来选择不同版本,这次我们使用Windows系统部署,所以直接下载最下面的Windows版即可。
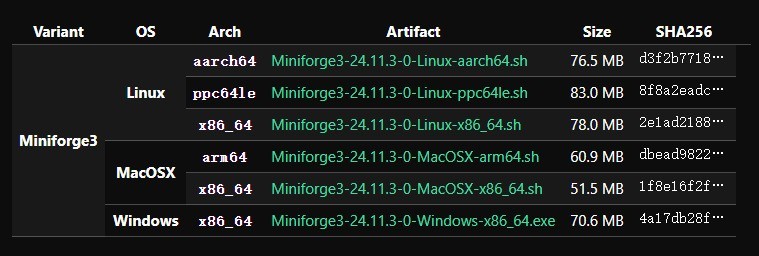
接下来先安装Miniforge.exe,然后建议把之前下载好的convert.py和run_moonlight-16b-a3b-instruct.py拷贝到C盘根目录,或者自定义位置也行,不过要记住两个文件的路径。
做好准备工作之后,在开始菜单里的“推荐的项目”里找到Miniforge Prompt并打开。

稍等一会儿显示盘符路径之后依次复制如下代码来完成模型的下载以及转换(每输入完一段代码都要敲回车)
cd /
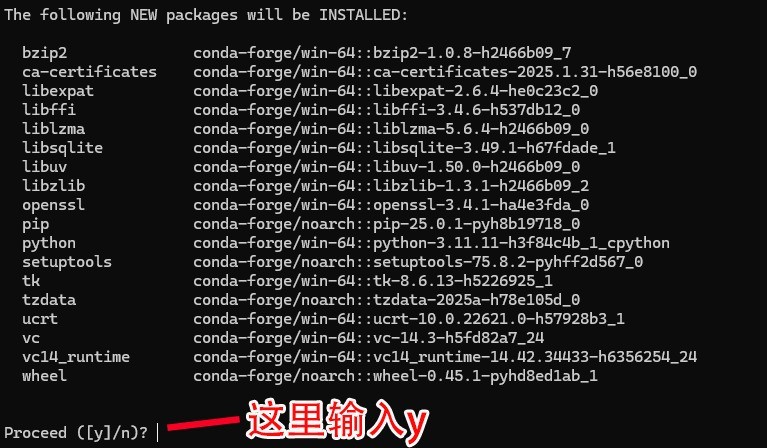
conda create -n ipex-llm python=3.11 libuv
【输入第二条代码之后稍等一会,然后输入y,并等待环境安装完成】
conda activate ipex-llm
【输入上面代码之后,前面的base会变成ipex-llm】

之后依次输入下面两行代码下载moonlight-16B-A3B-Instruct大语言模型:
pip install modelscope
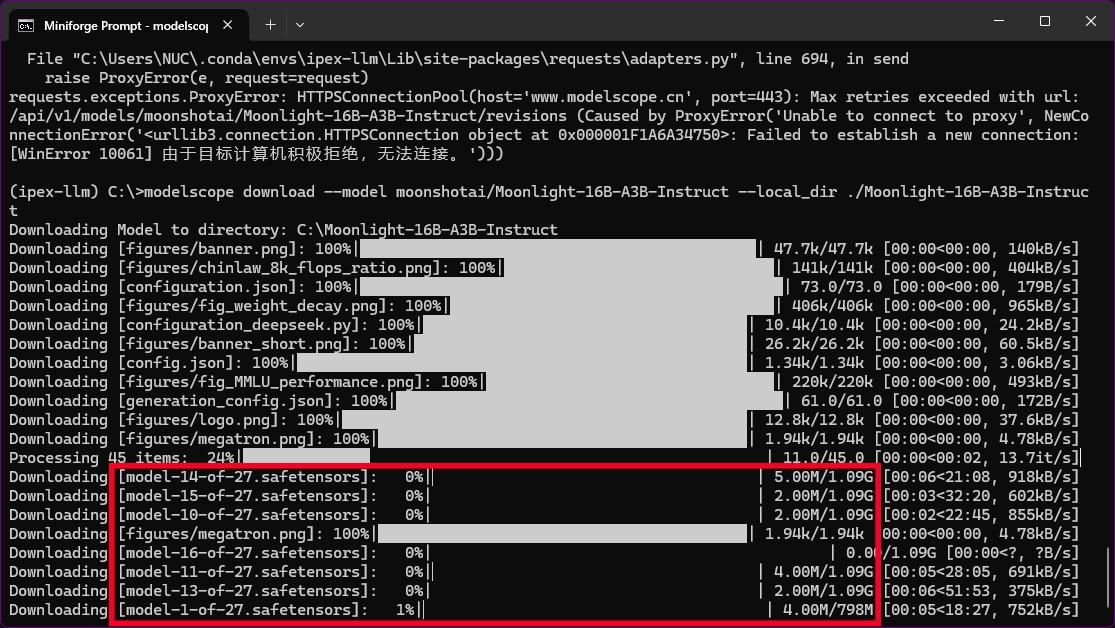
modelscope download --model moonshotai/Moonlight-16B-A3B-Instruct --local_dir ./Moonlight-16B-A3B-Instruct
【如下图所示,红框标出的大模型文件一共有27个,而全部文件有45个,下载完成后Processing 45 items:后面的百分数会达到100%】
模型下载根据自身网速快慢会不同,耐心等待下载结束后,继续依次输入下方3条代码:
pip install --pre --upgrade ipex-llm[xpu_2.6] --extra-index-url https://download.pytorch.org/whl/xpu -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install tiktoken blobfile transformers==4.45 trl==0.11 accelerate==0.26.0 -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install --pre --upgrade ipex-llm
此时就完成了moonlight-16B-A3B-Instruct大模型的下载与环境部署,之后我们需要确认大模型文件的位置,比如笔者是直接在C盘根目录中的。
接下来还记得我们之前保存的convert.py文件吗?此时我们需要用记事本打开它,将下图红框所示位置的两处「C:\Users\Le\Documents」修改为你自己下载的大模型文件的位置,比如笔者是下载到了C盘根目录,所以就修改为「C:\Moonlight-16B-A3B-Instruct」和「C:\Moonlight-16B-A3B-Instruct-converted」就好了,修改完成之后直接保存即可。
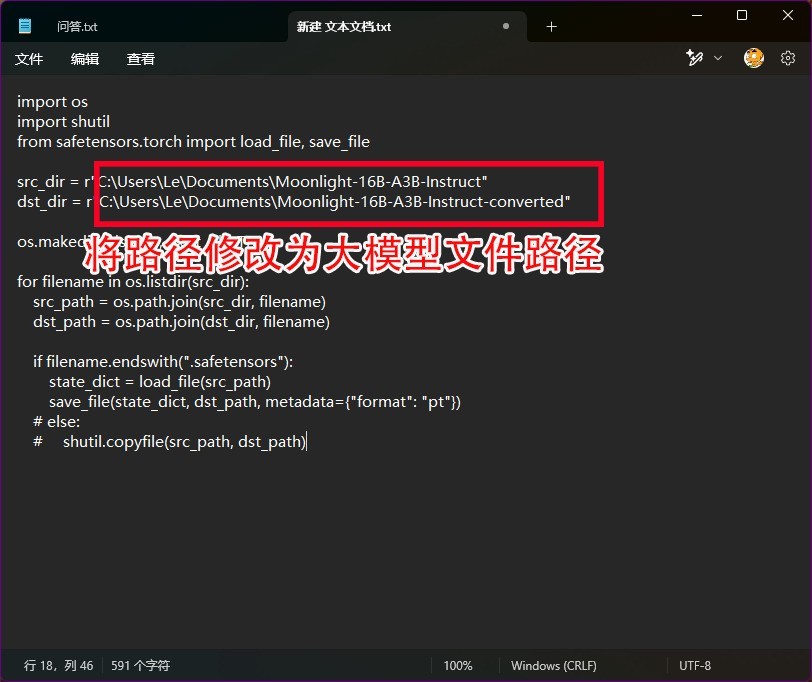
之后运行下方代码进行模型转换,整个过程全自动,无需做任何操作。
python convert.py
稍等片刻再次弹出「(ipex-llm)c:\>」,模型转换工作就完成了。之后将「C:\Moonlight-16B-A3B-Instruct」中的所有?件复制?「C:\Moonlight-16B-A3B-Instruct-converted」内,并在提?存在重复?件时跳过所有重复?件,一定要点击跳过,不要覆盖,大模型到此就完成了部署。
接下来再依次输入下面4条代码运行模型,即可愉快地使用本地moonlight-16B-A3B-Instruct AI助手了。
conda activate ipex-llm
set SYCL_CACHE_PERSISTENT=1
set SYCL_PI_LEVEL_ZERO_USE_IMMEDIATE_COMMANDLISTS=1
python run_moonlight-16B-A3B-instruct.py
之后如果想再次使用的话,只需要从conda activate ipex-llm这条指令开始即可。
【重要】此外,如果运行最后一条代码后出现下方报错提示:
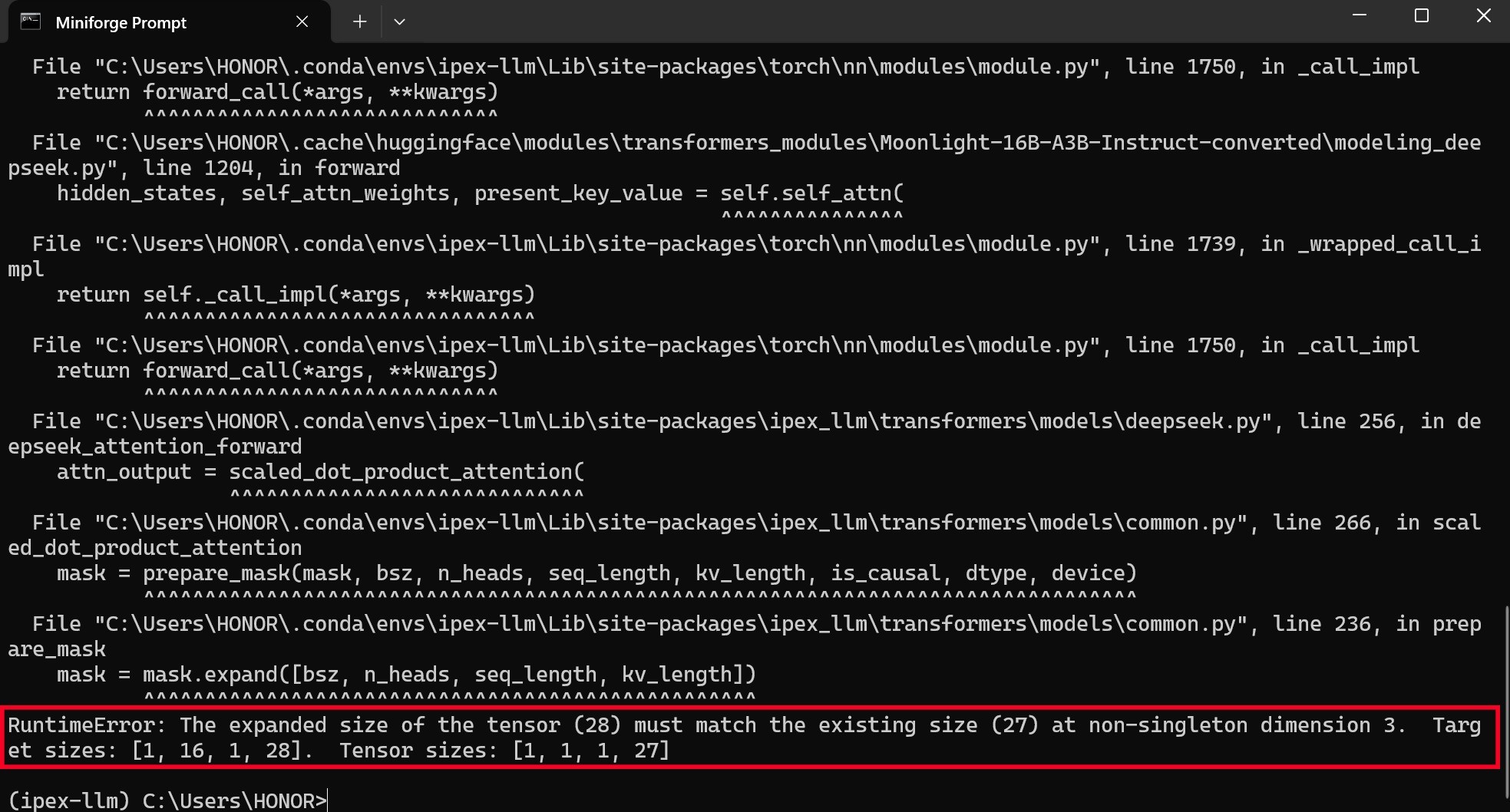
那么可以在「C:\Moonlight-16B-A3B-Instruct-converted」文件夹内,找到modeling_deepseek.py文件,通过记事本打开之后,Ctrl+F呼出搜索栏,输入max_cache找到下图代码,将get_seq_length()中的「seq」修改为「max」,之后保存,再输入python run_moonlight-16B-A3B-instruct.py命令,即可成功运行大模型。

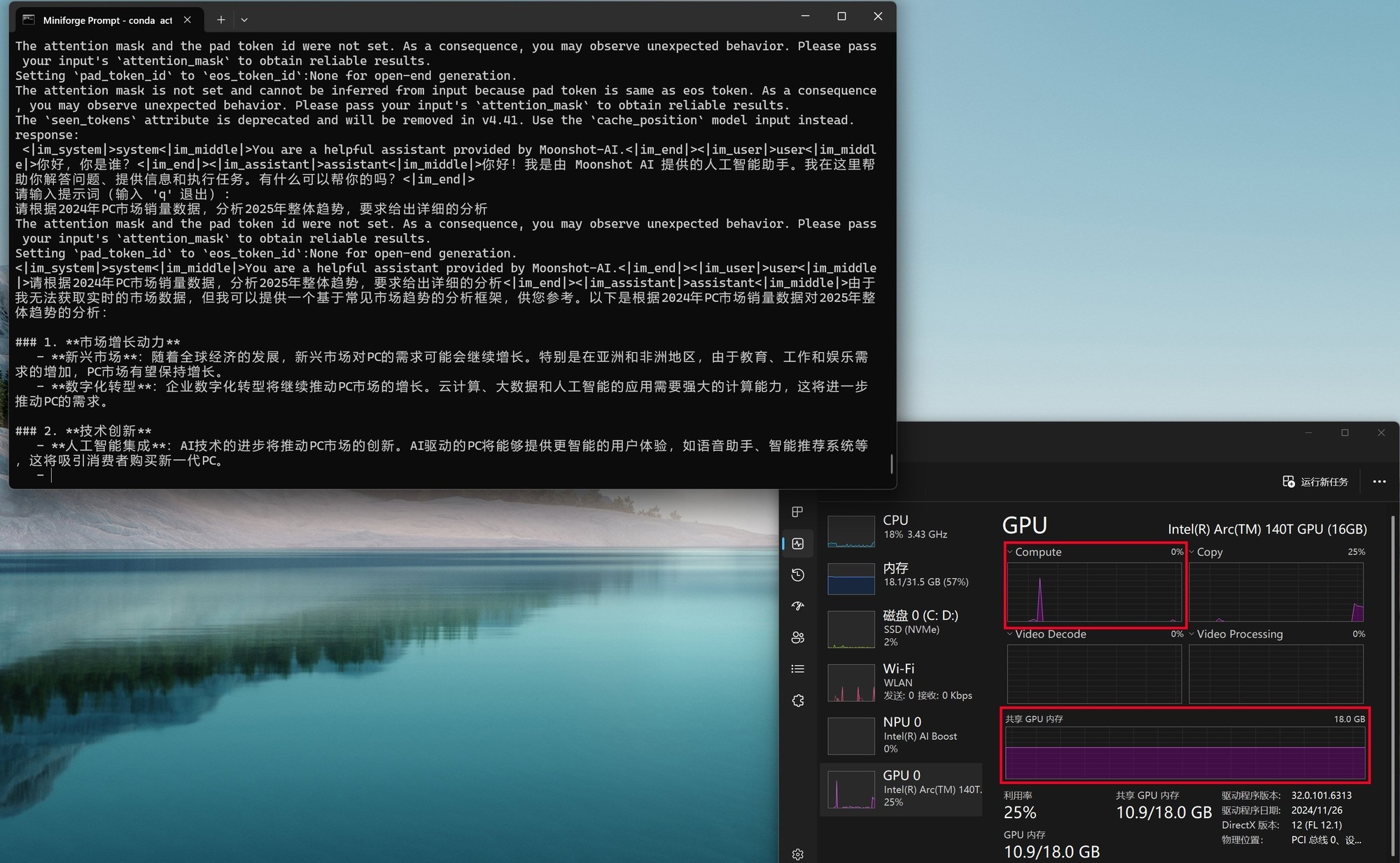
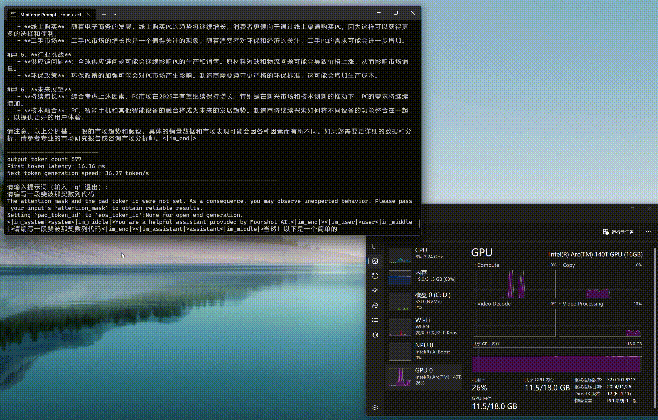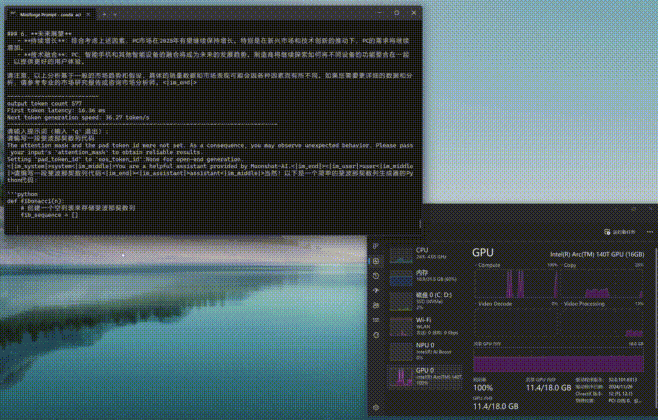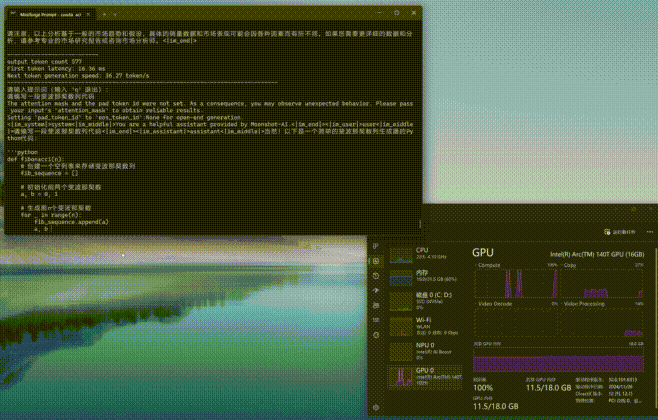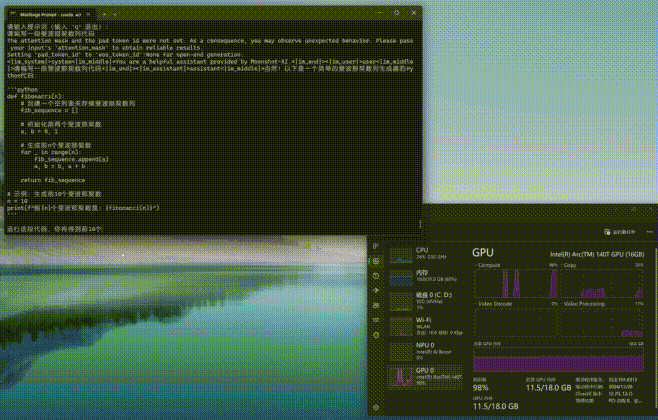
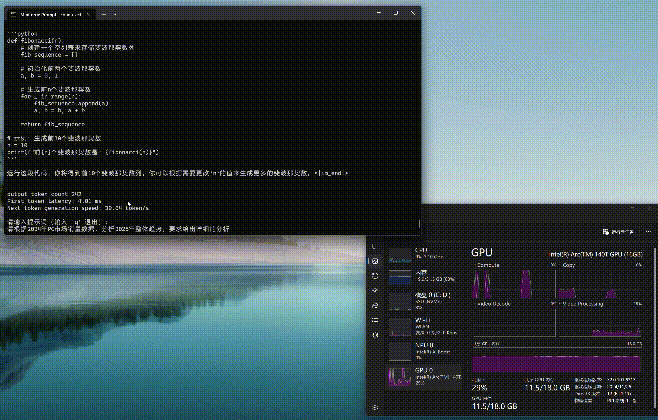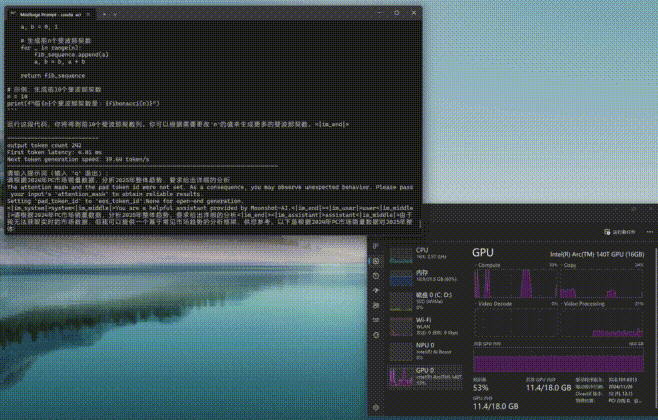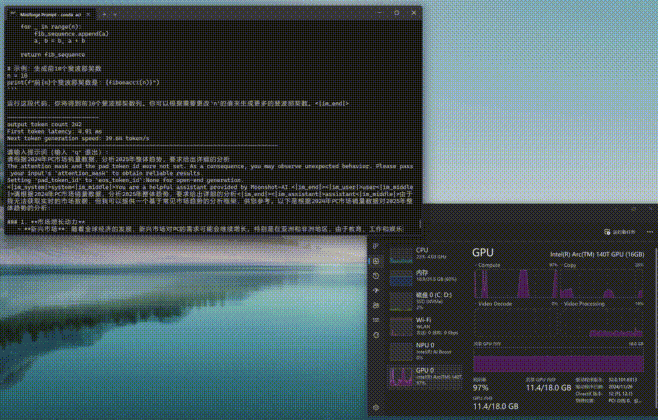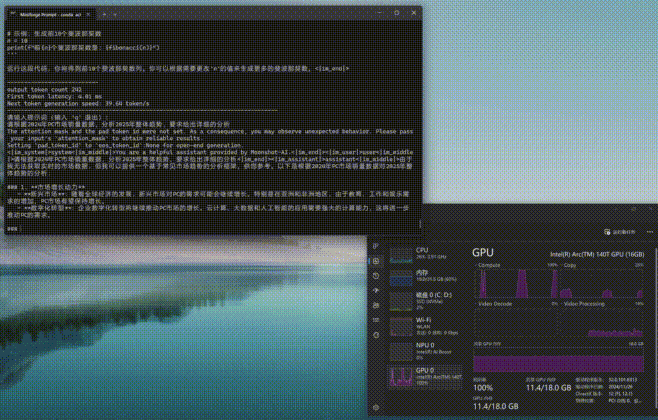
与Ollama和Flowy不同的是,moonlight工作时更加依赖GPU共享显存,而Compute负载非常低。从下图可以看到,moonlight-16B-A3B-instruct进行推理时,GPU显存占用率会明显上升,另外内存的占用率也不低。
这里需要补充说明的一点是,在部署moonlight时,之前使用的Ultra 5 225H平台已归还厂商,所以我们找来了另外一台Ultra 9 285H+锐炫140T核显的平台。虽然二者在传统性能上差异不小,但单纯的AI算力方面其实相差并不大。
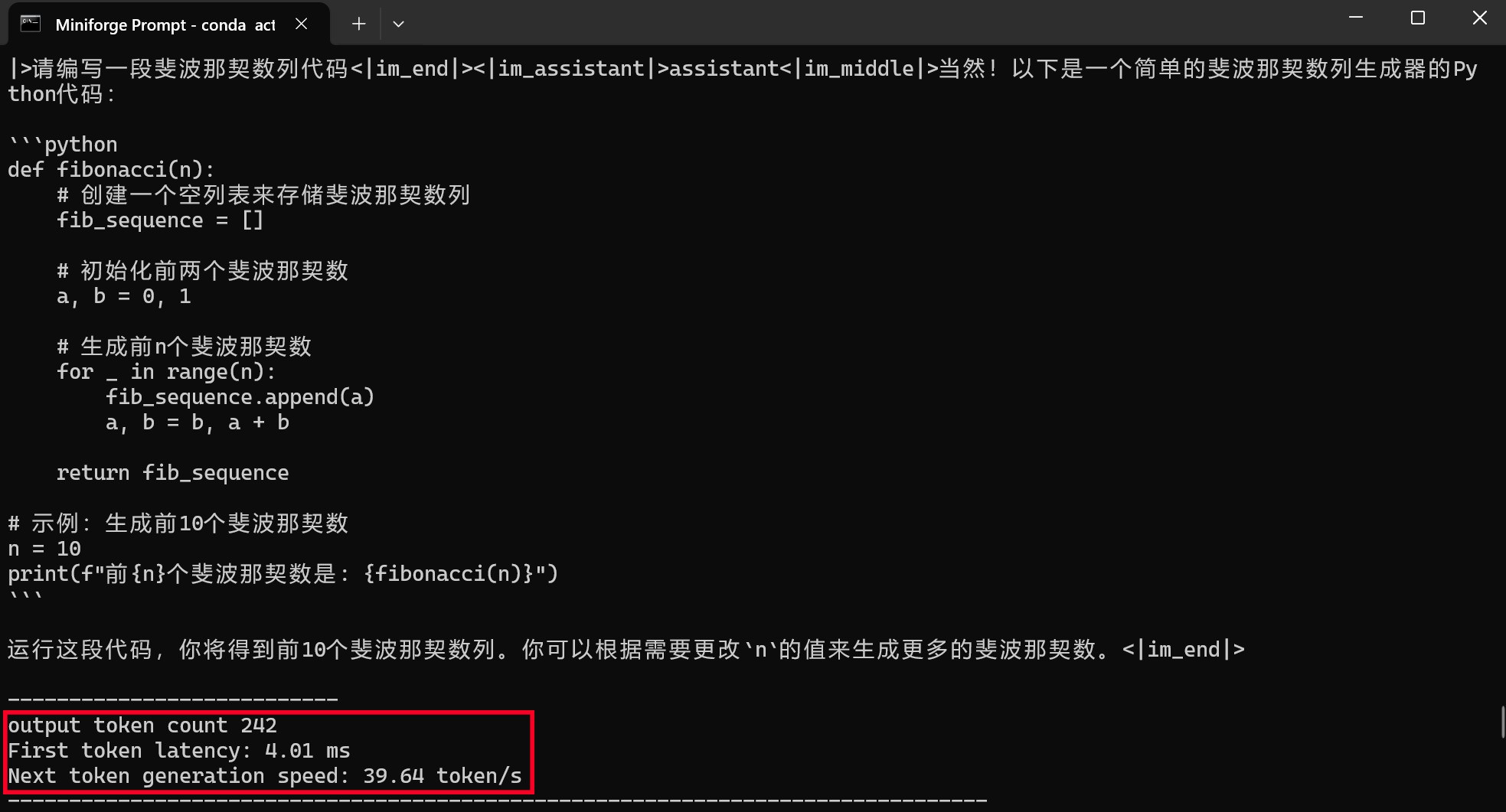
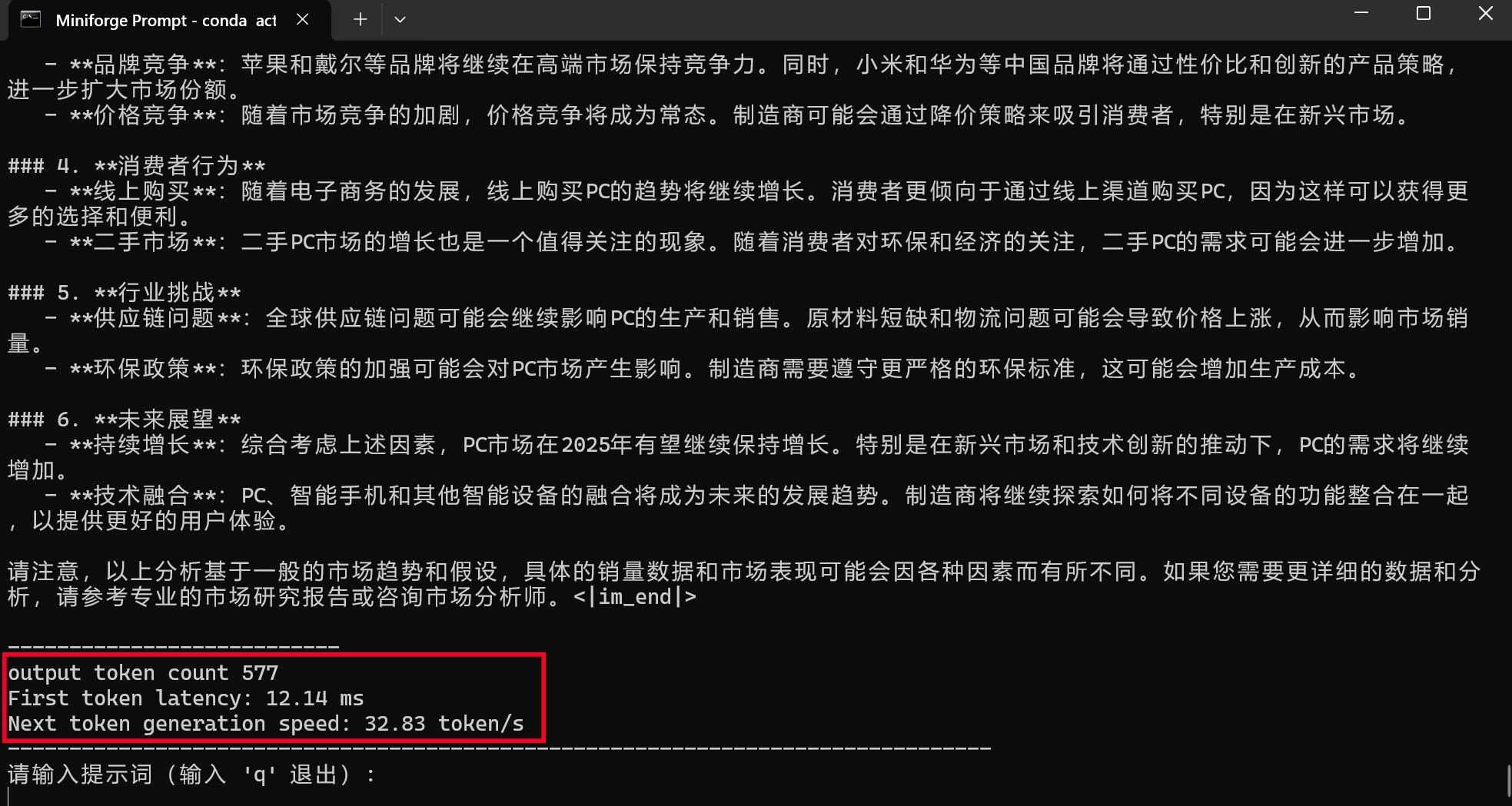
通过moonlight-16B-A3B-instruct大模型进行编程或问答,编程时的First token耗时仅为4.01毫秒,平均速度达到了39.64tokens/s,速度可以说是相当快了。而问答时的First token耗时为12.14毫秒,略高一些,但是平均速度也能达到32.83tokens/s,看来支持英特尔ipex-llm框架的模型跑到酷睿Ultra平台上确实是速度相当快,满足日常使用没有任何效率上的不足。(下方GIF图均为1倍速录制)
·英特尔酷睿Ultra 200H平台理论AI性能测试
了解了如何在酷睿Ultra 200H AI PC上部署本地DeepSeek-R1大语言模型以及如何使用之后,我们不妨看看酷睿Ultra 200H的理论AI算力如何?以及它为什么能够在本地运行时也能够提供非常快速的生成体验?
「UL Procyon理论与应用测试」
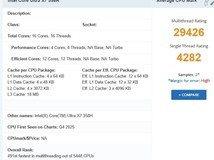
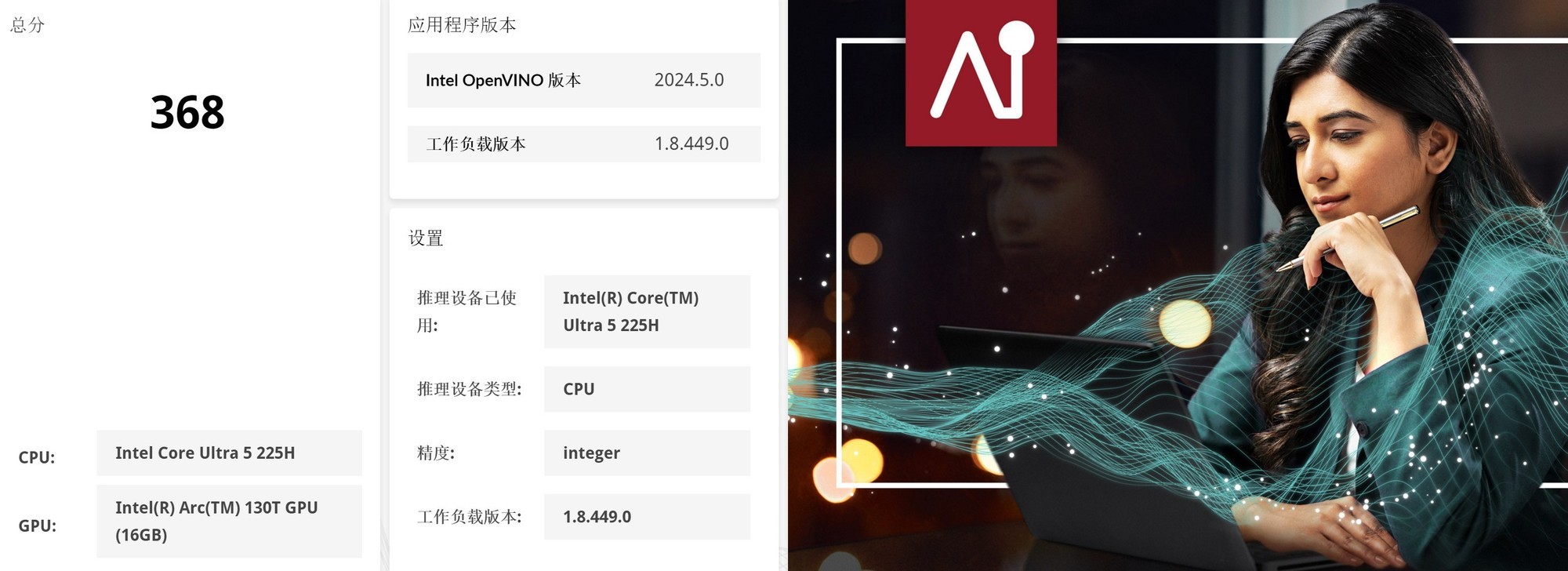
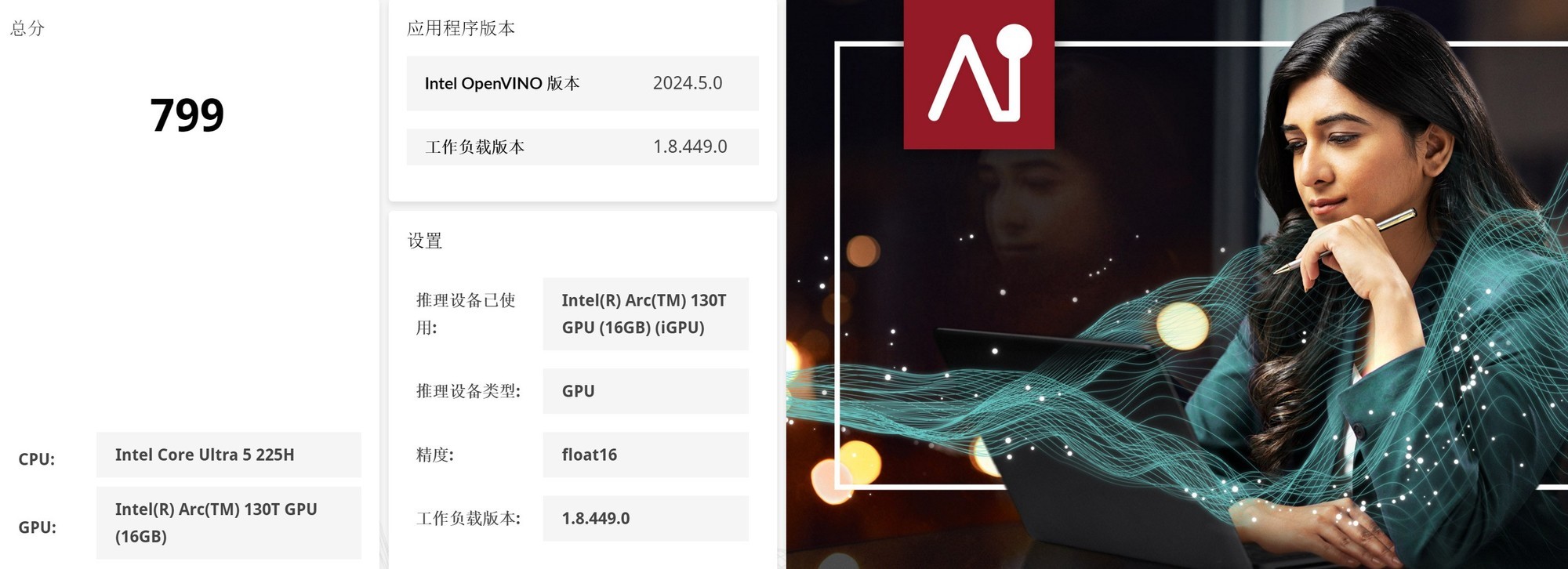
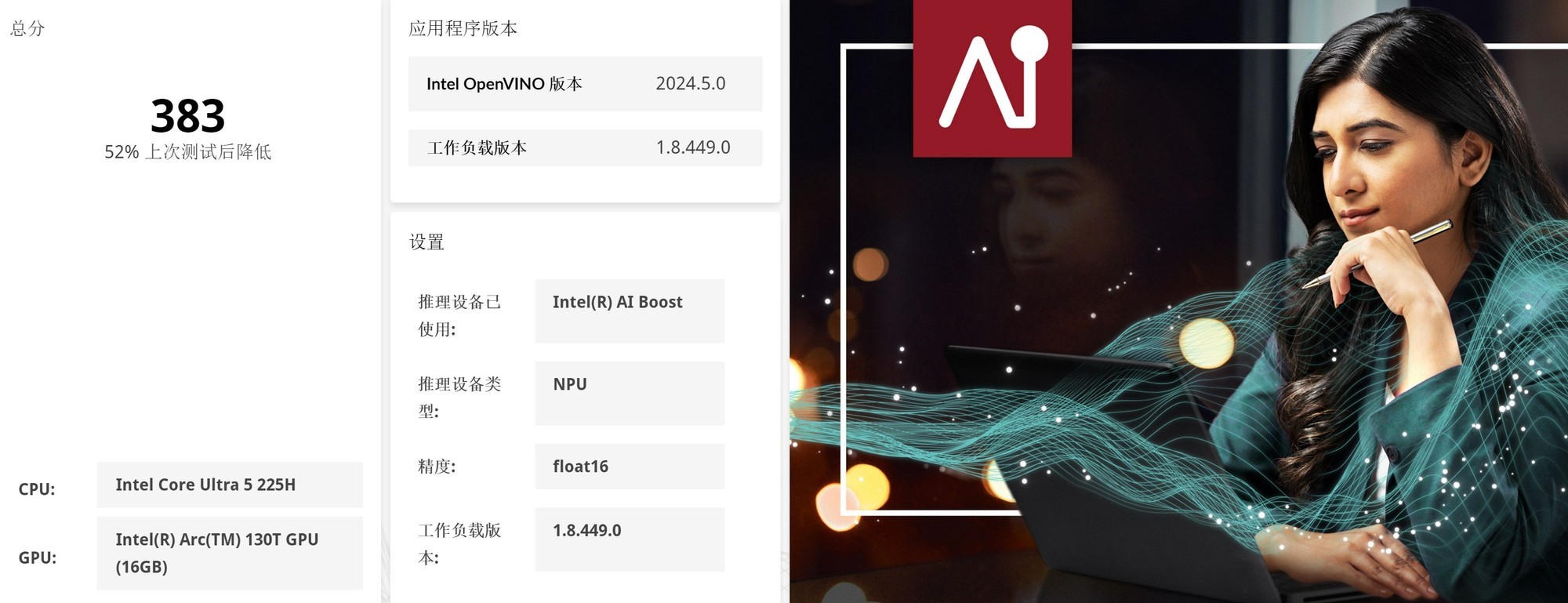
首先来看看UL Procyon的CPU、GPU、NPU理论性能测试。在Intel OpenVINO加速下,英特尔酷睿Ultra 5 225H的CPU整数AI算力评分368,GPU Float16 AI算力评分799,NPU Float16 AI算力评分383。对比第一代酷睿Ultra 9 185H平台,第二代酷睿Ultra 5 225H平台的CPU、GPU、NPU AI算力分别提升323%、71%以及141%!
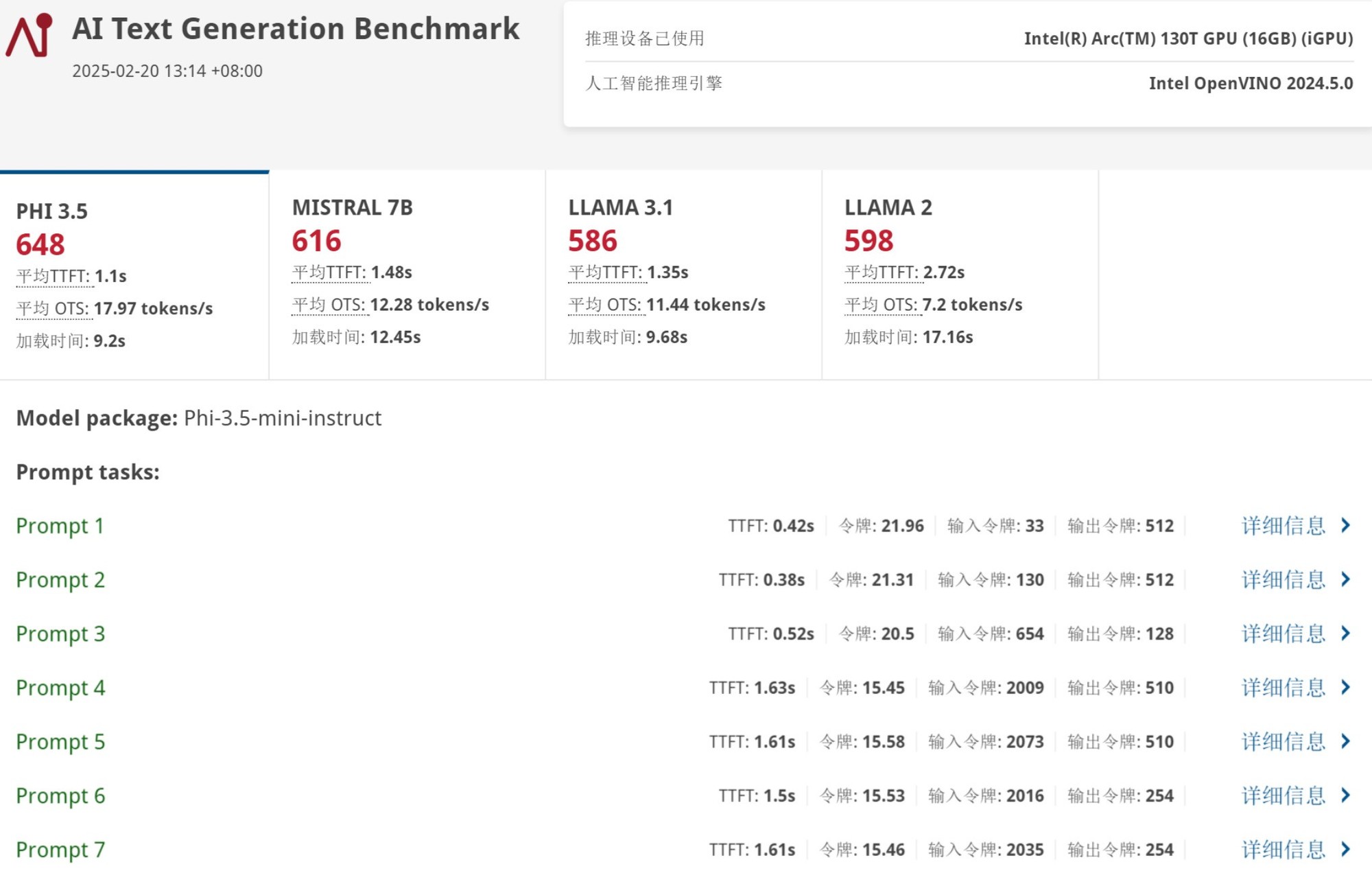
接下来我们看看酷睿Ultra 5 225H平台在AI文本生成测试中的表现。下图可以看到,UL Procyon文本生成测试中也完全占用了GPU Compute。
该项测试主要包含Phi-3.5、Mistral 7B、Llama 3.1以及Llama 2四种大语言模型,酷睿Ultra 5 225H平台分别得分648、616、586以及598分。
Phi-3.5平均生成速度为17.97 tokens/s,Mistral 7B平均生成速度为12.28 tokens/s,Llama 3.1平均生成速度为11.44 tokens/s,Llama 2平均生成速度为7.2 tokens/s。
「tokens即大语言模型生成文本、字段、符号的单位,生成速度用tokens/s表示。比如,“我们今天学习AI知识。”这句话,大语言模型会对句子信息拆分成:我们丨今天丨学习丨AI丨知识丨。丨这些单字、词以及句号就是1个token」
酷睿Ultra 9 285H平台则是搭载了锐炫140T核显,不过CPU性能与Ultra 5 225H有比较大差异,但GPU方面其实相差不大,因此两个平台做AI来说整体性能差异感受并不明显。
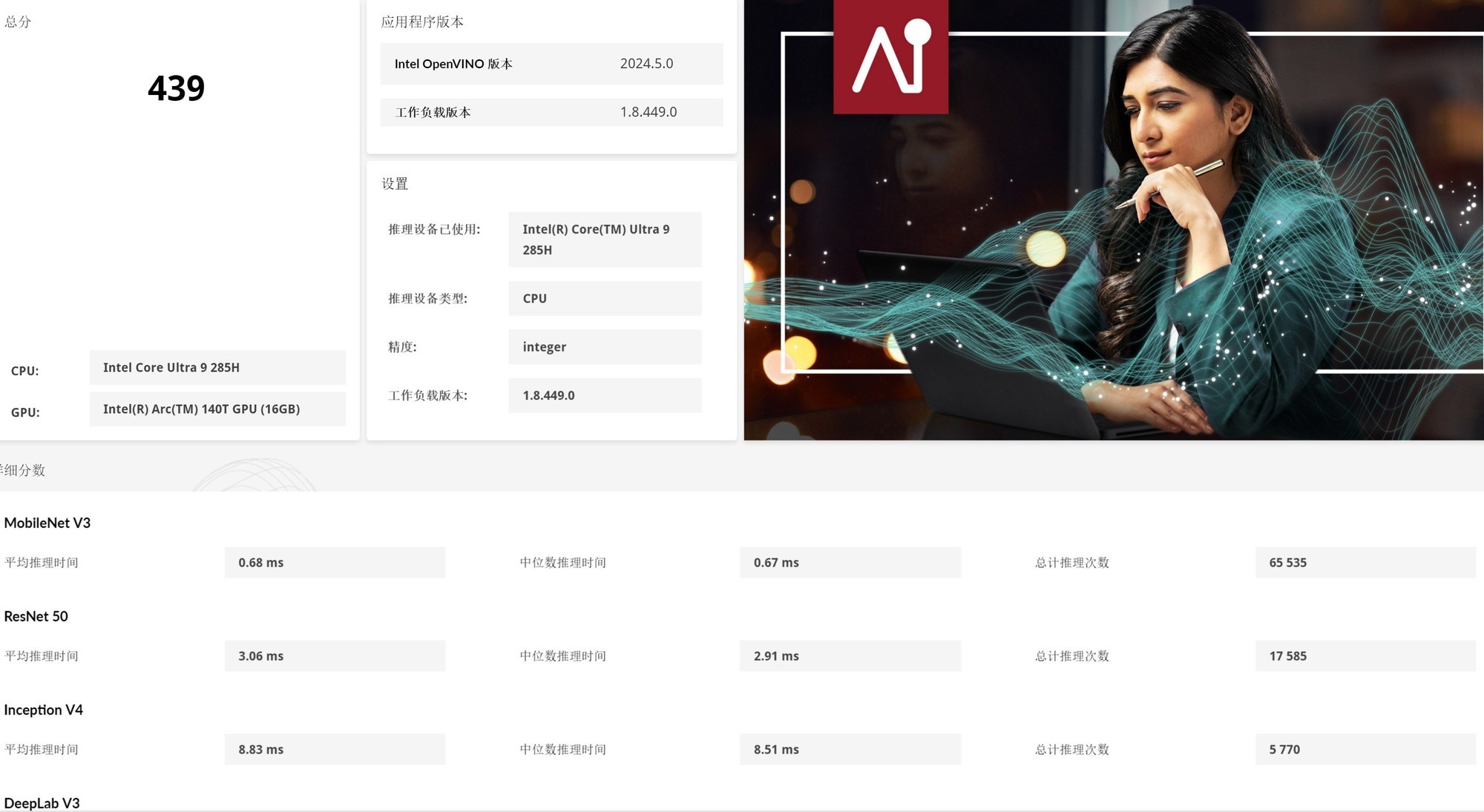
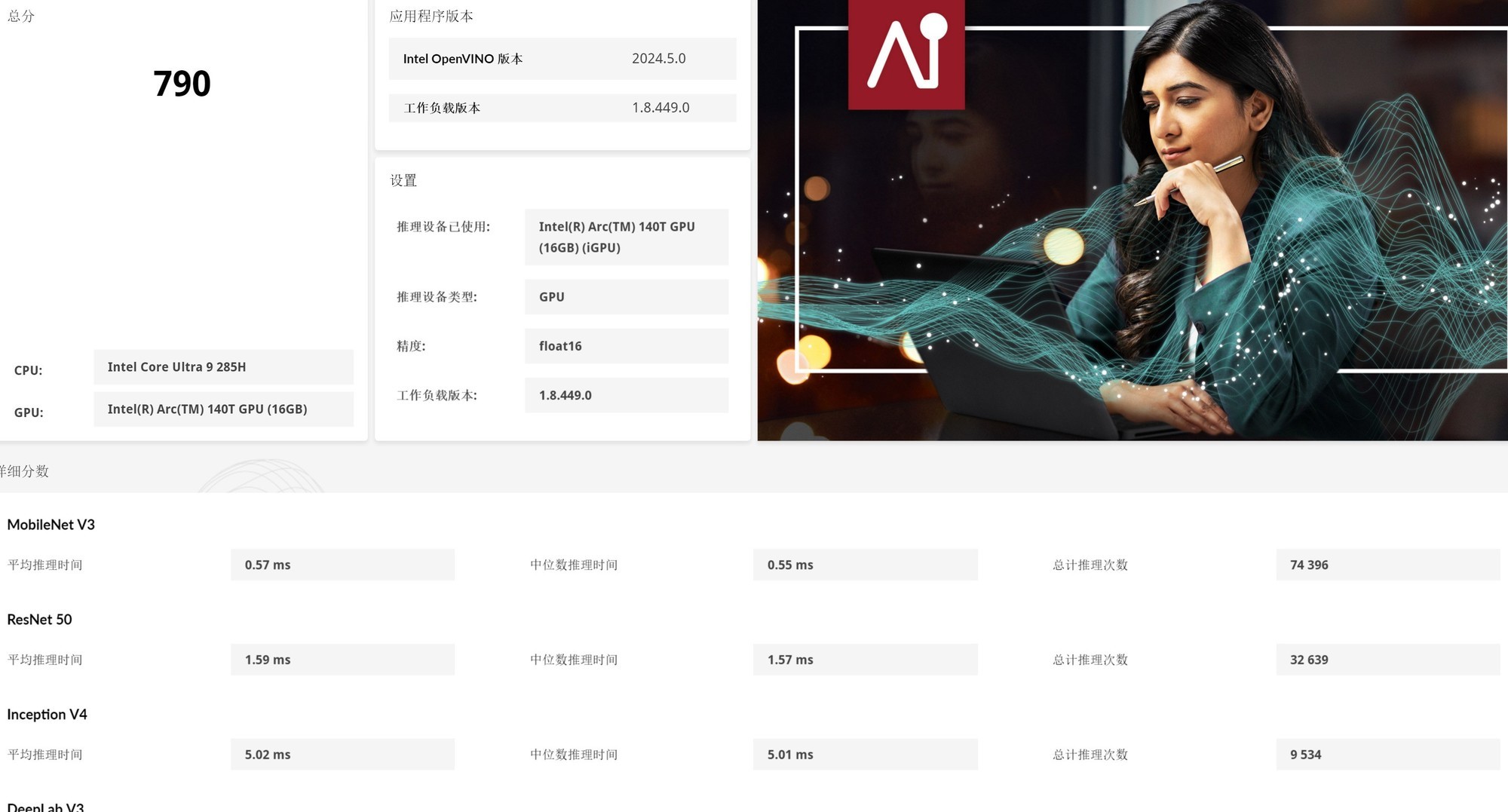
在Intel OpenVINO加速下,英特尔酷睿Ultra 9 285H的CPU整数AI算力评分439,GPU Float16 AI算力评分790,NPU Float16 AI算力评分366。
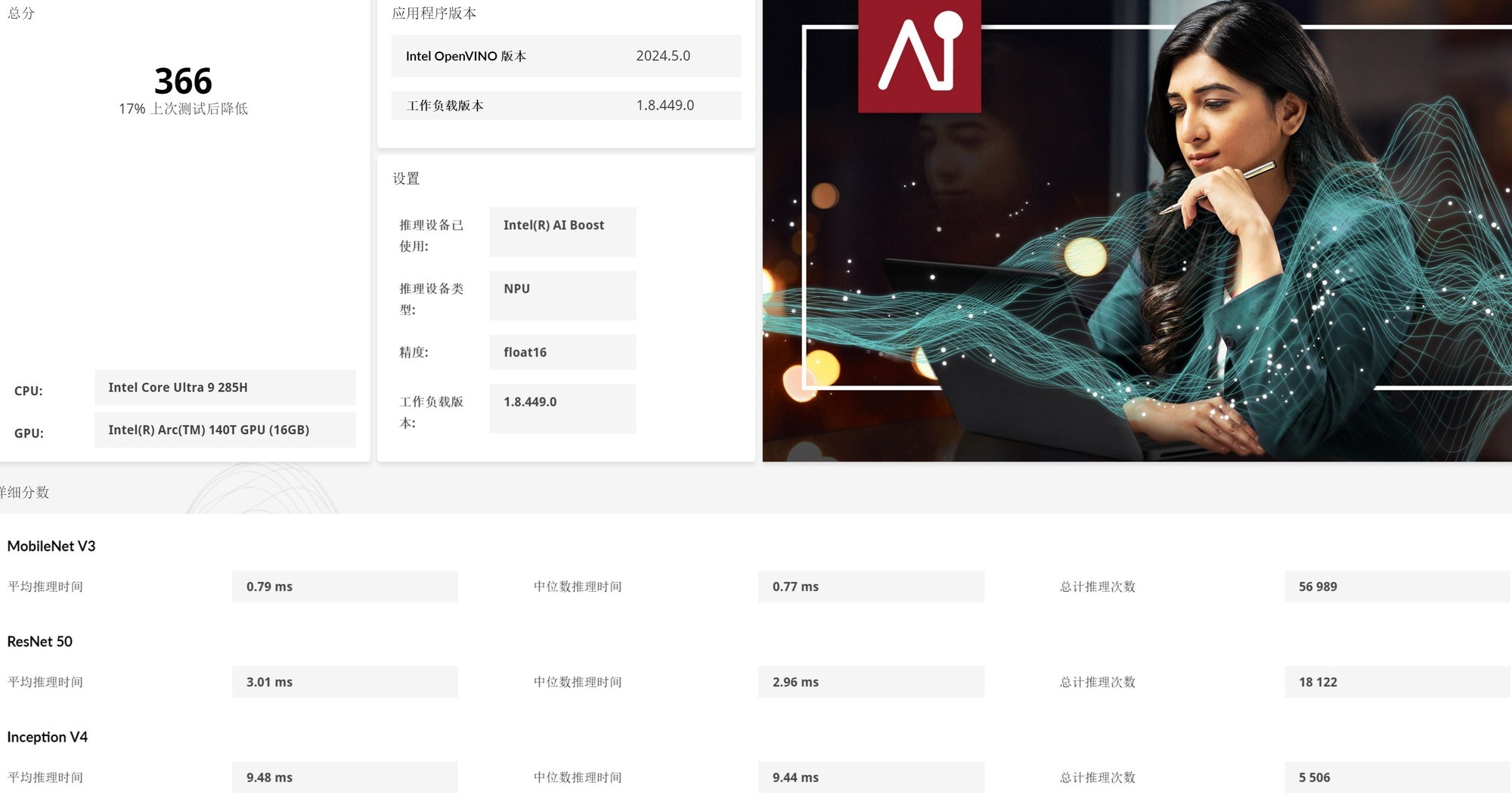
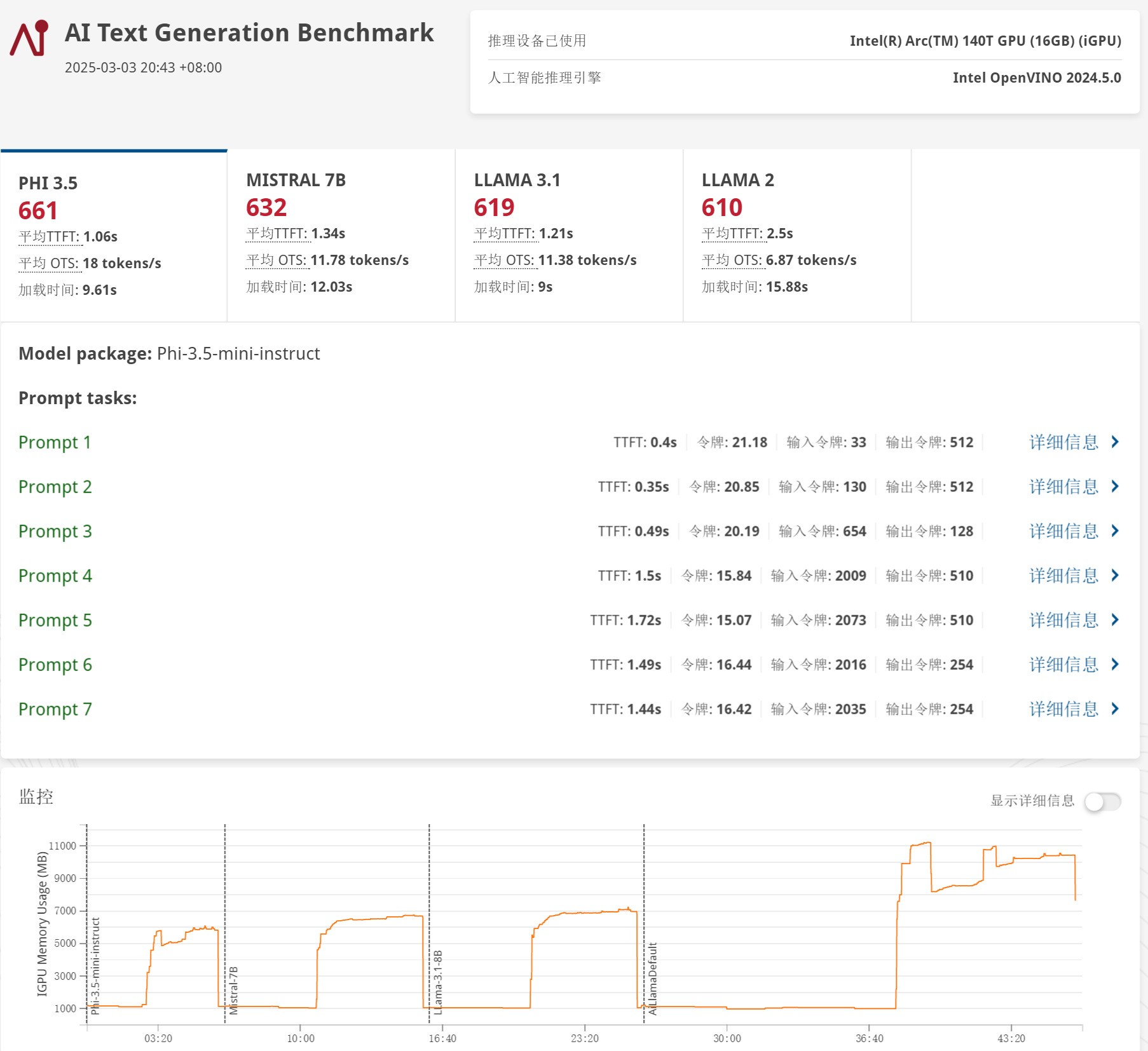
接下来的AI文本生成测试中,酷睿Ultra 9 285H平台分别得分661、632、619以及610分,整体比酷睿Ultra 5 225H要高一些。
具体到四个大语言模型的速度,Phi-3.5平均生成速度为18 tokens/s,Mistral 7B平均生成速度为11.78 tokens/s,Llama 3.1平均生成速度为11.38 tokens/s,Llama 2平均生成速度为6.87 tokens/s,与Ultra 5 225H平台没有明显差异。所以无论是高配还是主流配置,第二代酷睿Ultra在AI应用方面的体验整体表现都非常不错,对于不同预算的朋友来说都能提供很好的AI计算能力。
「MLPerf Client基准性能测试」
接下来我们引入一个全新的测试——MLPerf Client基准性能测试,这是由MLCommons开发的一款基准测试工具,旨在评估个人电脑(包括笔记本、台式机和工作站)上大型语言模型(LLMs)和其他AI工作负载的性能。它通过模拟真实世界的AI应用场景,如AI聊天机器人和图像分类等,为用户提供清晰的性能指标,帮助用户理解系统处理生成性AI工作负载的能力。
因为这款测试工具支持Intel OpenVINO加速,这可以使我们更好地了解酷睿Ultra平台跑AI的实际表现。通过下图可以看到,MLPerf在测试时同样会占满GPU Compute。
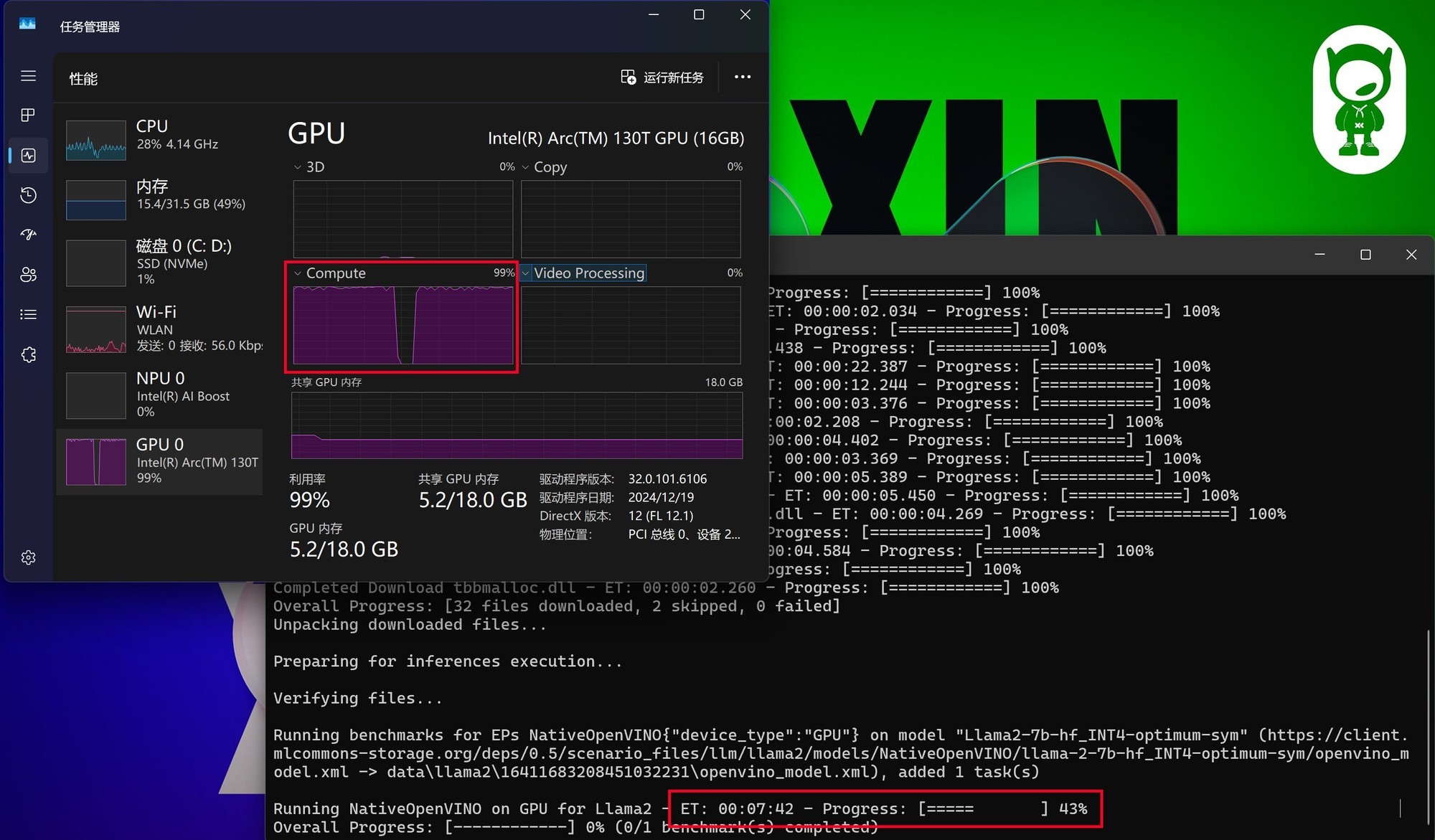
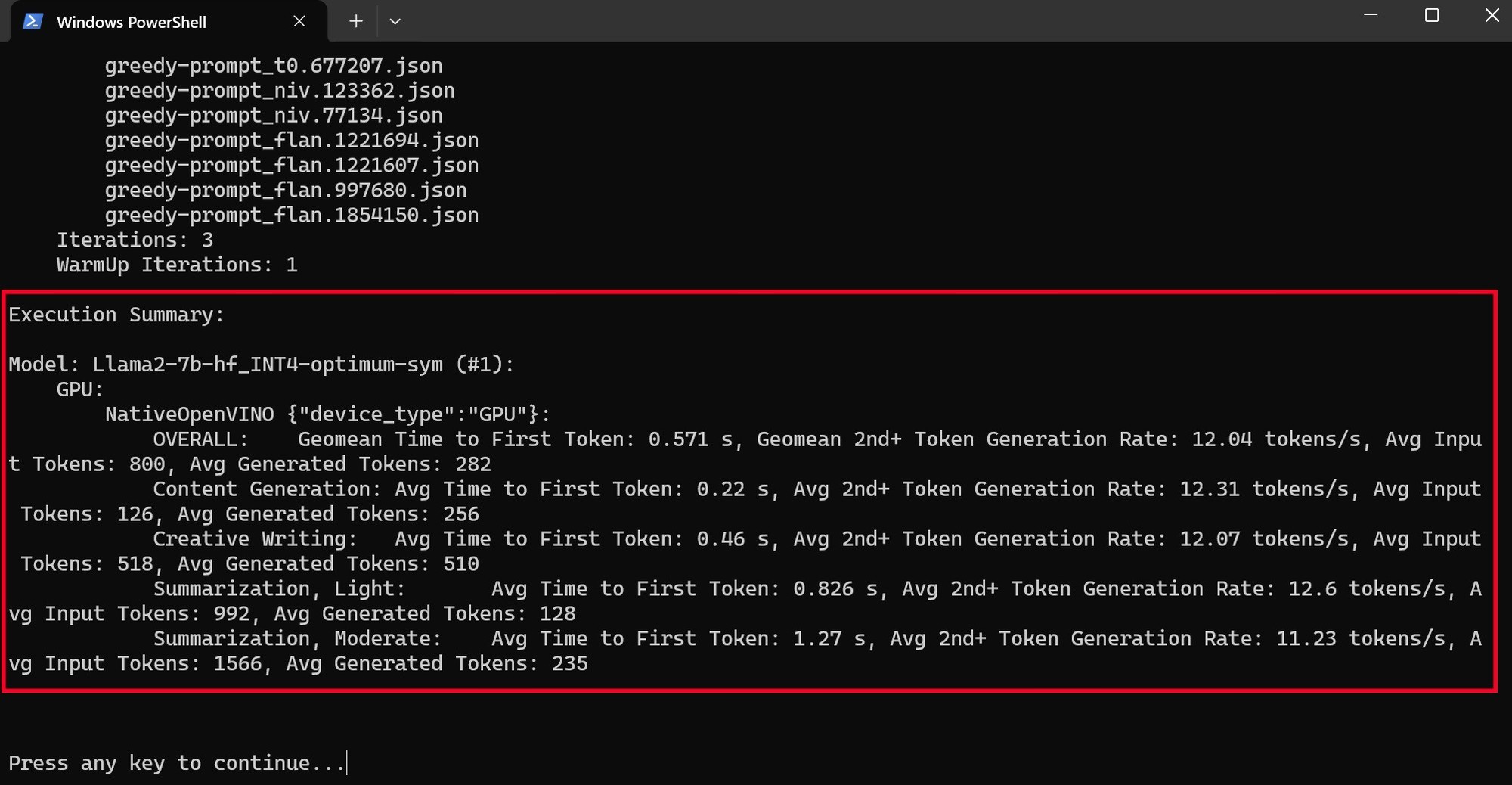
MLPerf在测试时使用了Llama2-7B_INT4模型,总体来说对硬件的要求并不算高,First token时间不到1秒,平均速度为12.91 tokens/s,因此酷睿Ultra 5 225H平台部署本地化AI是基本没有性能方面的问题的。
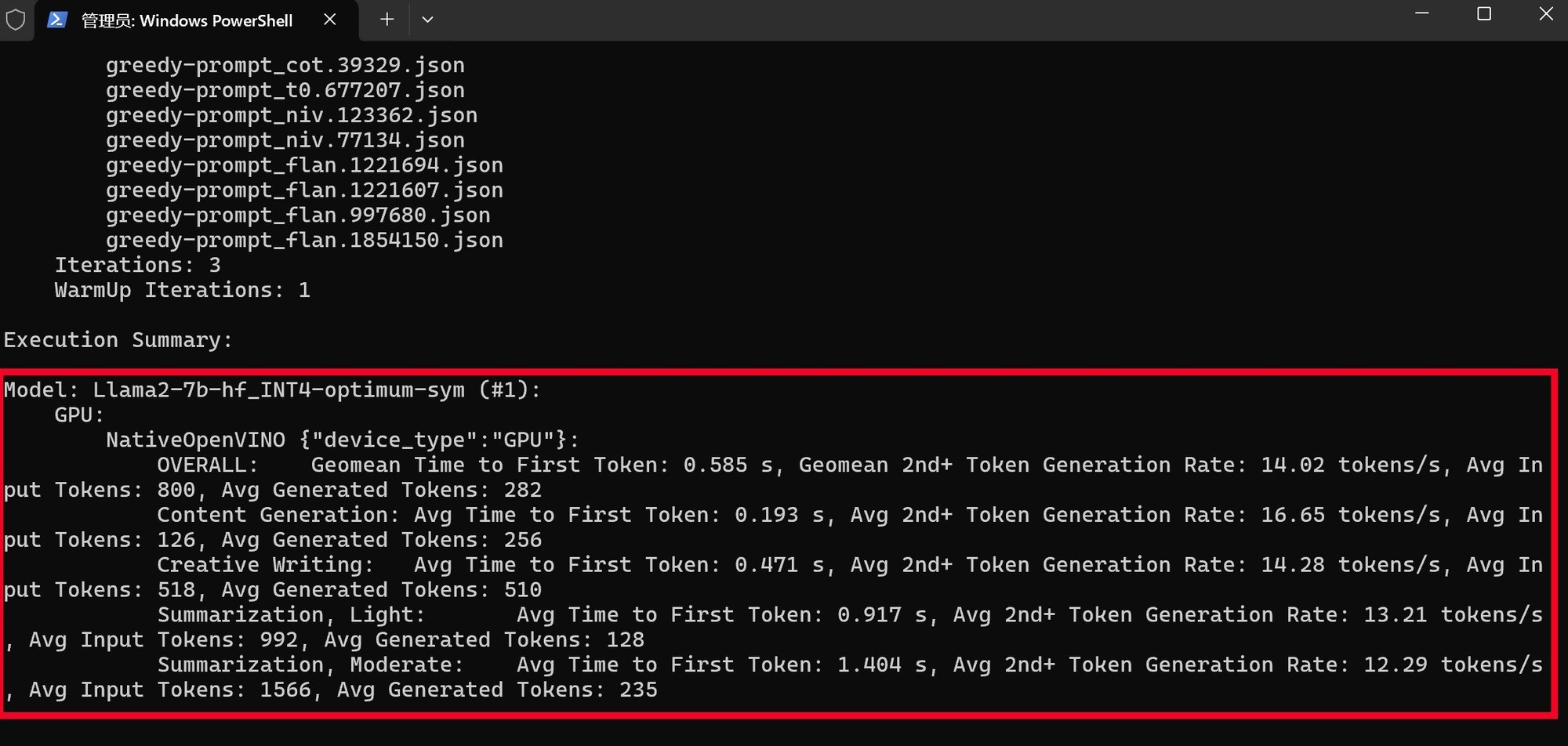
酷睿Ultra 9 285H平台在MLPerf测试中,First token时间同样不到1秒,平均速度为12.05 tokens/s,与酷睿Ultra 5 225H平台无差别。
·结语
DeepSeek、moonlight这些国产大语言模型的成功落地,对于AI PC在大众层面的认知和普及有着极为重要的推动作用。此前人们可能只知道有AI PC这个概念,但具体是什么、怎么用、和传统PC有怎样的区别等等却并不是很清楚。而DeepSeek、moonlight引发的探索热情,则可以让更多用户了解这些问题的答案。
同时,基于英特尔酷睿Ultra系列处理器打造的AI PC,可以说是性能体验最好、稳定性最好、兼容性最好的本地化AI部署平台。Ollama、Flowy、LM Studio、Miniforge等常用软件全部支持,并且支持Intel OpenVINO加速,再加上酷睿Ultra 200系列平台本身在CPU、GPU、NPU AI算力上几乎都实现了翻倍,因此无论是安装部署还是最终的使用以及性能体验,都实现了低门槛、高效率,这对于AI PC未来的发展意义深远,同时可以让更多用户更加轻松地将AI助手部署到自己的日常工作、学习、生活环境中。
此外,本地化AI应用有着安全、隐私、便利、不依赖网络以及低使用成本的特性,能够让用户随时随地、安全私密地借助AI来提升自己的工作、学习效率。因此,如果你想将DeepSeek、moonlight这样的大语言模型部署到本地使用,那么英特尔酷睿Ultra AI PC绝对是当前非常不错的选择。
本文属于原创文章,如若转载,请注明来源:简单又安全 用酷睿AI PC实现零门槛本地AI助手部署https://nb.zol.com.cn/956/9561236.html