人工智能应用落地,是伴随AI PC行业发展的主旋律。AMD、NVIDIA、英特尔这些上游芯片厂商搭出硬件台子,自然需要有人登台唱戏,这样才能够让AI PC的发展步入快车道。
2025开年,DeepSeek成为了让全世界瞩目的登台者,且倍受行业和用户认可。但是对于大众用户而言,如何将DeepSeek部署到自己的AI PC设备上?当前AI PC硬件能否顺利支持大容量数据模型?
今天咱们就来聊聊这些问题。
·AMD哪些硬件支持DeepSeek R1大模型?
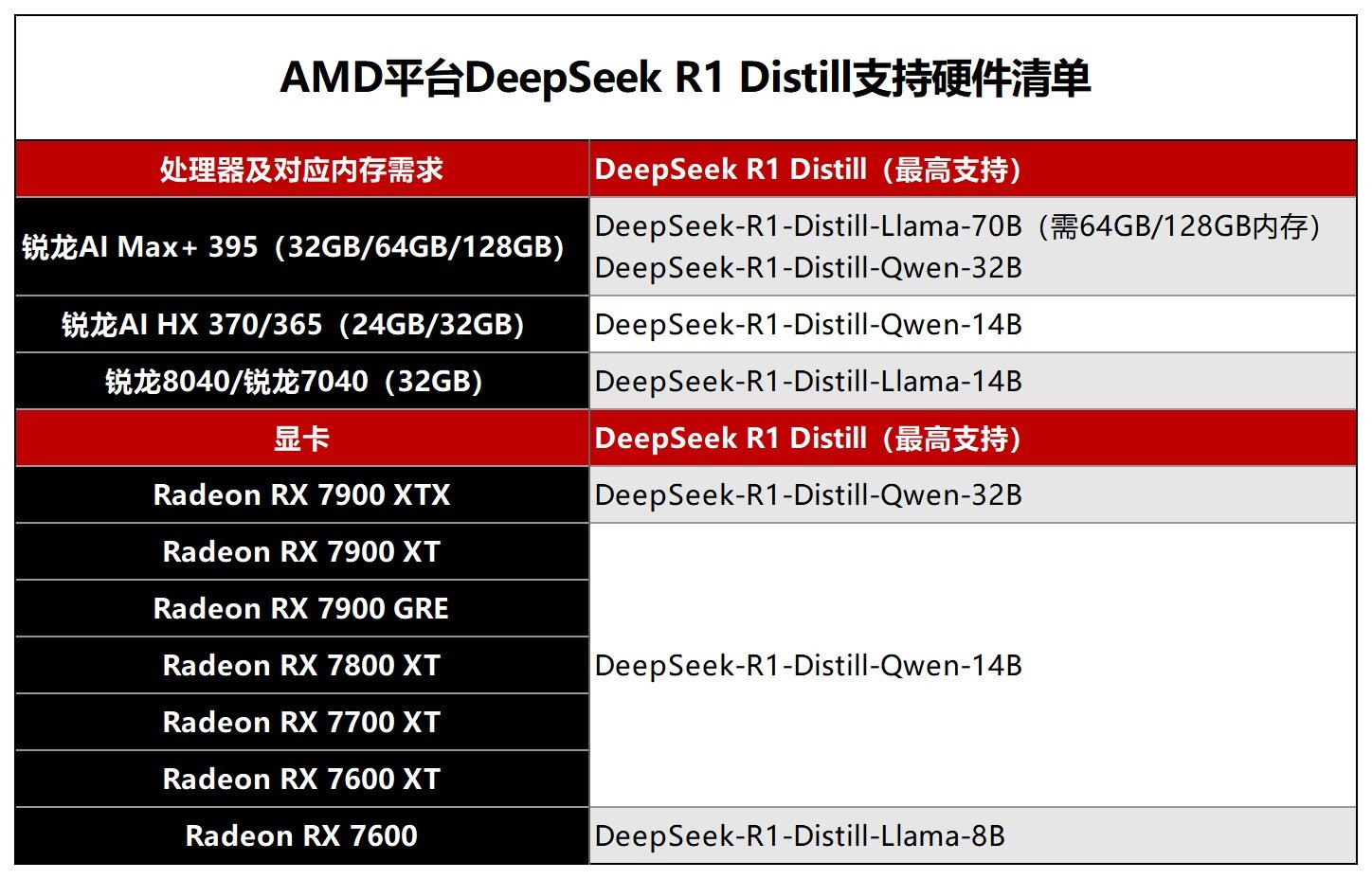
前几天,AMD发布了DeepSeek R1 Distill推理模型可被应用于AMD Ryzen AI处理器和Radeon显卡上的博客,并公布了对应的处理器型号、内存需求、显卡型号,以及相应的DeepSeek R1 Distill大模型的规格,具体如下:
作为当前备受认可的前沿推理模型,DeepSeek R1已经被提炼成为功能强大的小型模型,算力需求成本低,效果好,而且部署起来非常便捷。
·测试平台硬件配置信息
本次我们使用LM Studio这款软件对DeepSeek R1进行了本地化部署,所使用的硬件平台配置如下:
CPU:AMD锐龙AI 9 HX PRO 375
GPU:AMD Radeon 890M iGPU
内存:64GB LPDDR5X
硬盘:2TB PCIe 4.0固态硬盘
系统:Windows 11 24H2(26100.2161)
推理模型是一种新型的大型语言模型(LLMs),通过链式思维(CoT)推理来解决高度复杂的任务,其代价是响应时间较长,而且它对于GPU、内存性能的要求极高。
这次我们使用的AMD锐龙 AI 9 HX PRO 375平台没有配备独显,但既然AMD博客里提到锐龙AI HX 370/365这个等级的处理器可以支持DeepSeek-R1-Distill-Qwen-14B规格的大模型,那么锐龙 AI 9 HX PRO 375自然也能够胜任这项任务。
接下来,我们看看如何在自己的AI PC上部署一个能够在不联网情况下也能使用的“DeepSeek AI助手”,同时也看看没有独显的AMD锐龙平台AI PC在使用DeepSeek R1 Distill进行推理时会有怎样的表现?
·如何部署一个本地化的DeepSeek应用环境
「先期准备」
在开始部署DeepSeek R1之前,我们需要先做两个准备:
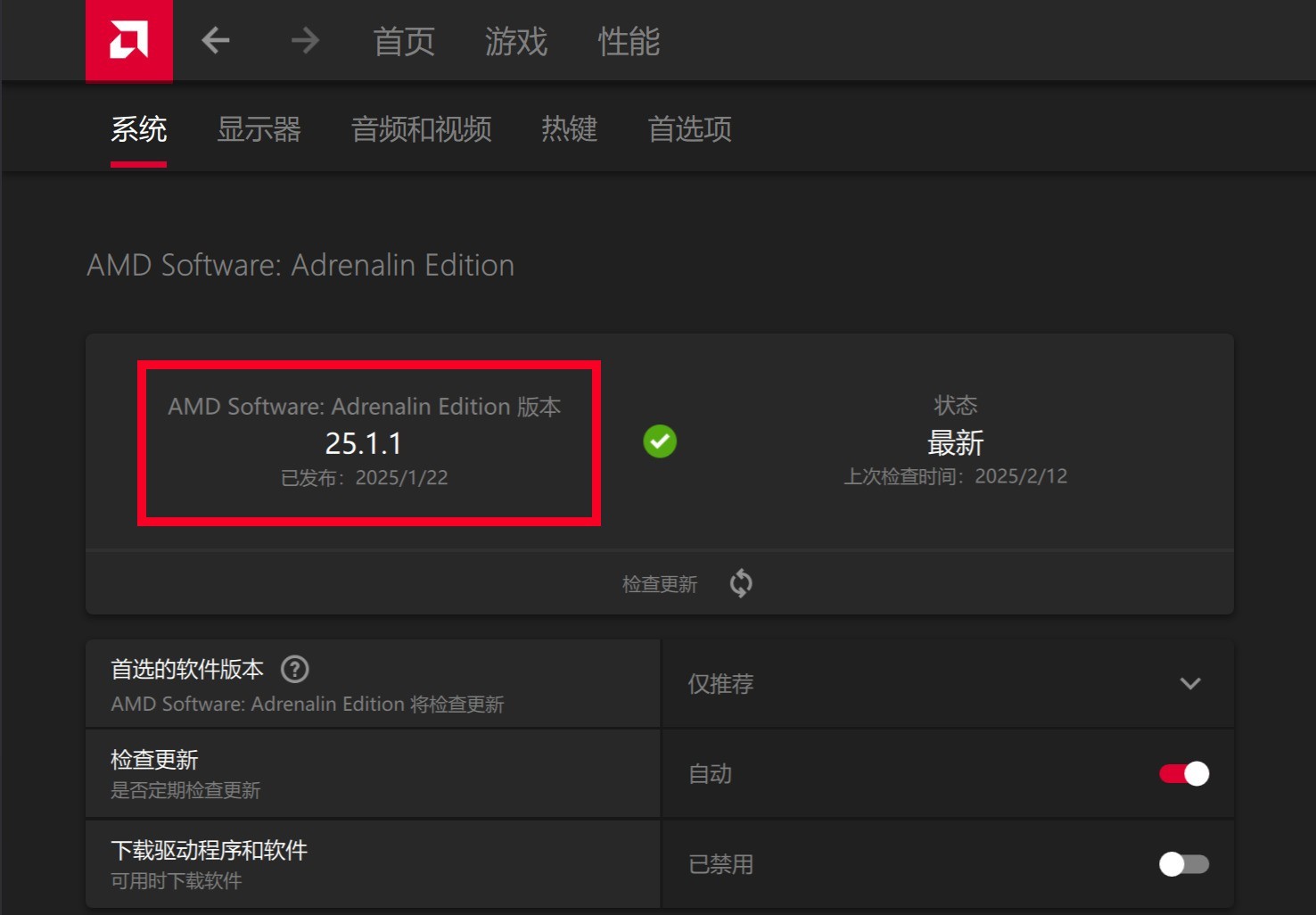
其一,升级驱动程序。将AMD Software:Adrenalin Edition升级到25.1.1及以上版本。【点击此处进入官网驱动程序下载页面】
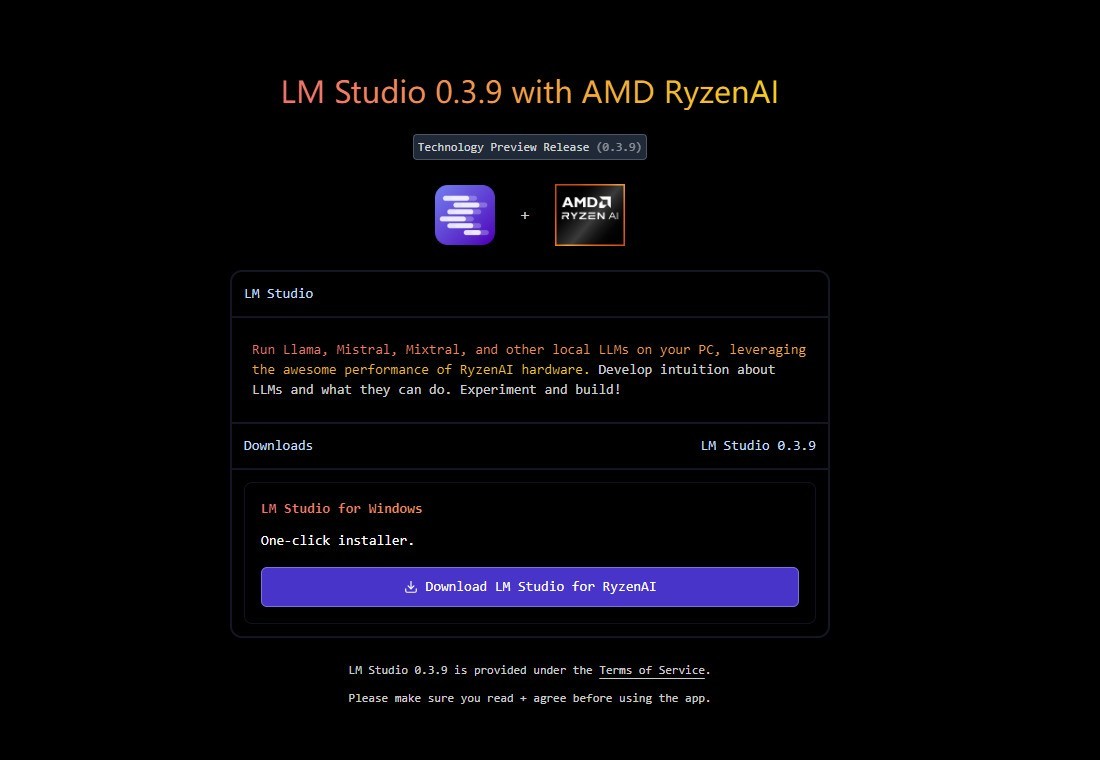
其二,下载LM Studio软件。目前最高版本为0.3.9。【点击此处进入官网下载LM Studio软件】
升级驱动并安装好LM Studio软件之后,需要重启电脑以使驱动程序生效。
「模型下载」
接下来让我们正式开始将DeepSeek R1 Distill部署到我们的AI PC上。
第一步:打开LM Studio软件之后,我们可以直接点击右上角跳过引导界面。
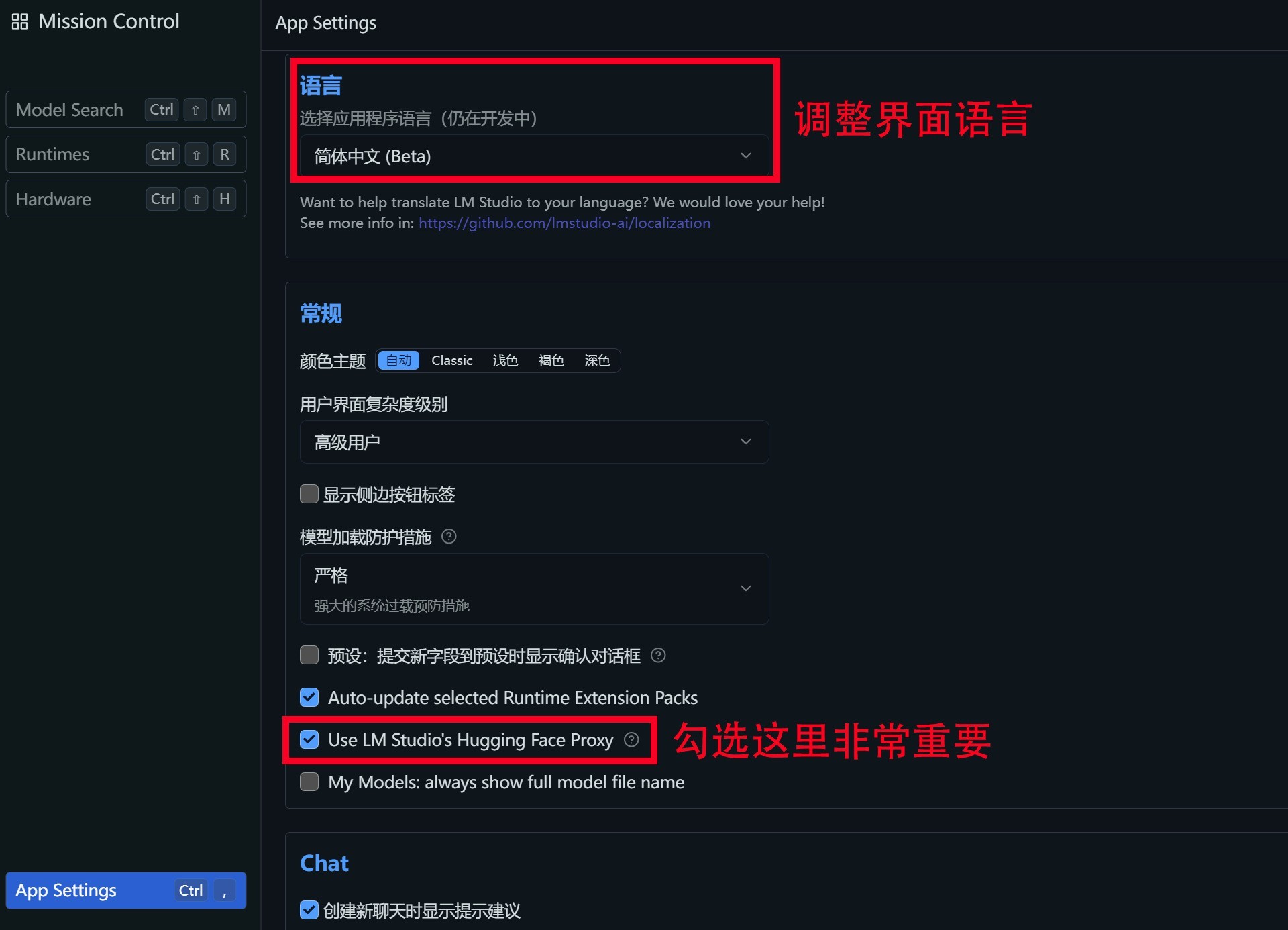
第二步:点击右下角齿轮图标,或者直接「Ctrl+,」快捷键打开应用程序设置界面。这里你可以将界面语言调整为中文。同时下拉滚动条找到Use LM Studio's Hugging Face Proxy选项,并在其左侧的方框里打勾选中。之后即可关掉应用程序设置界面。
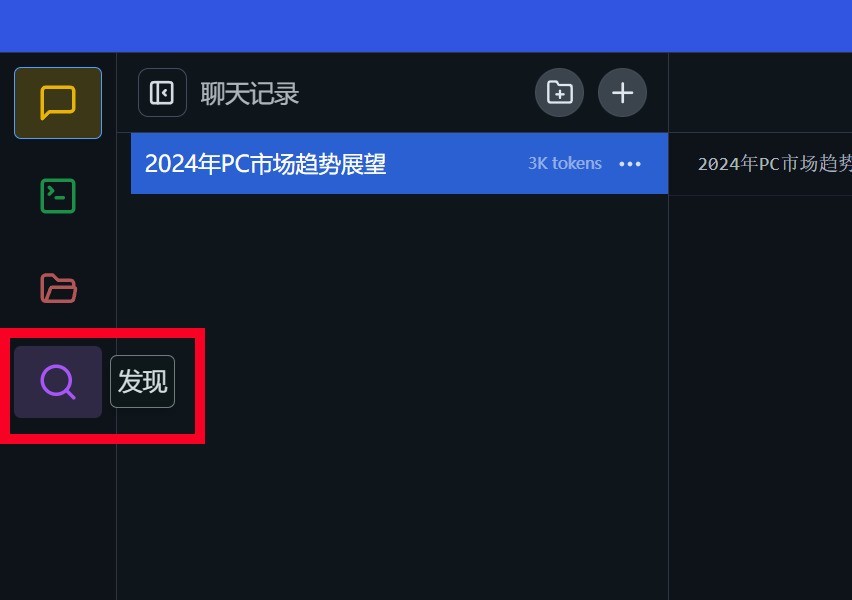
第三步:找到主界面左侧放大镜图标,也就是「发现」按钮,并点击打开模型搜索界面。
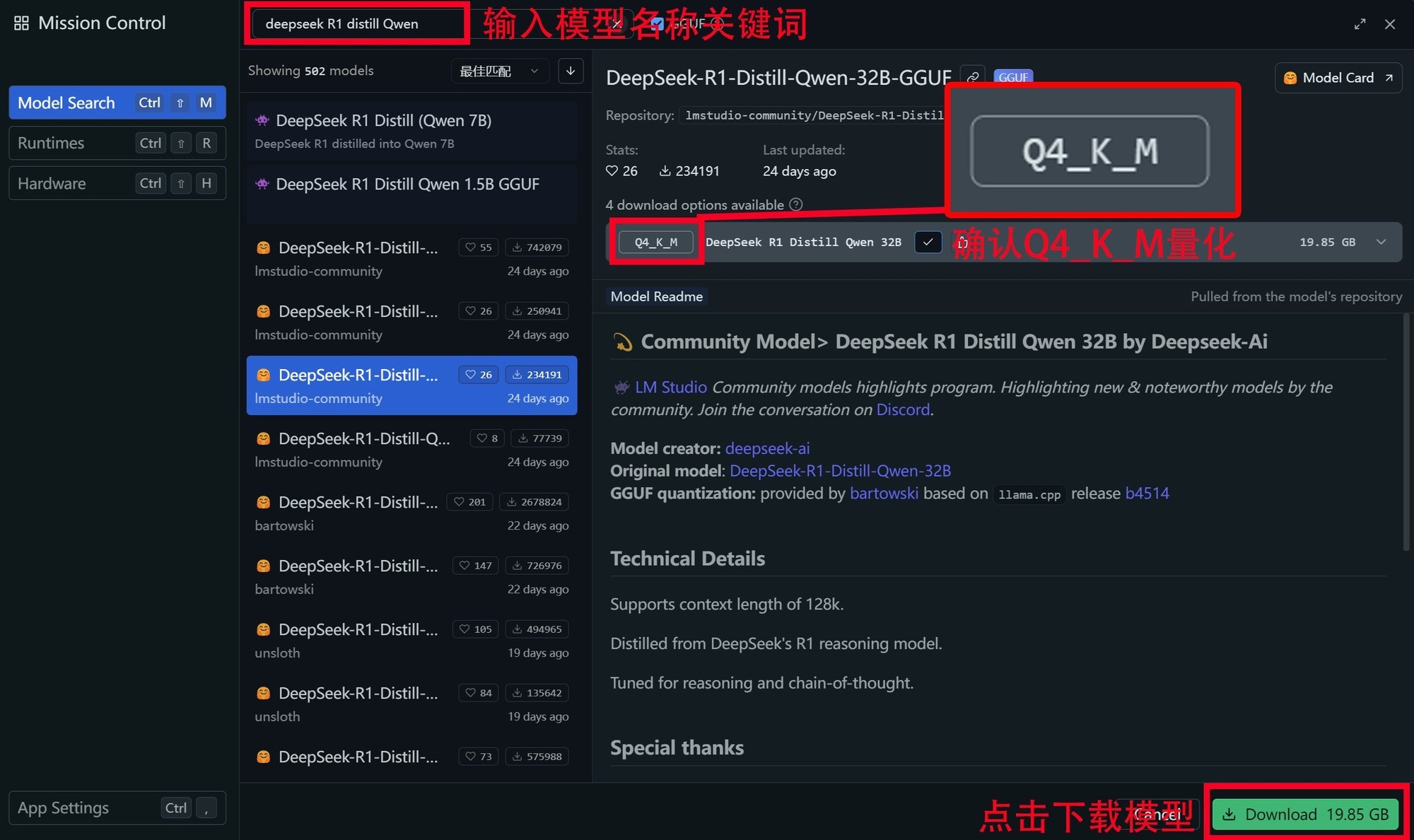
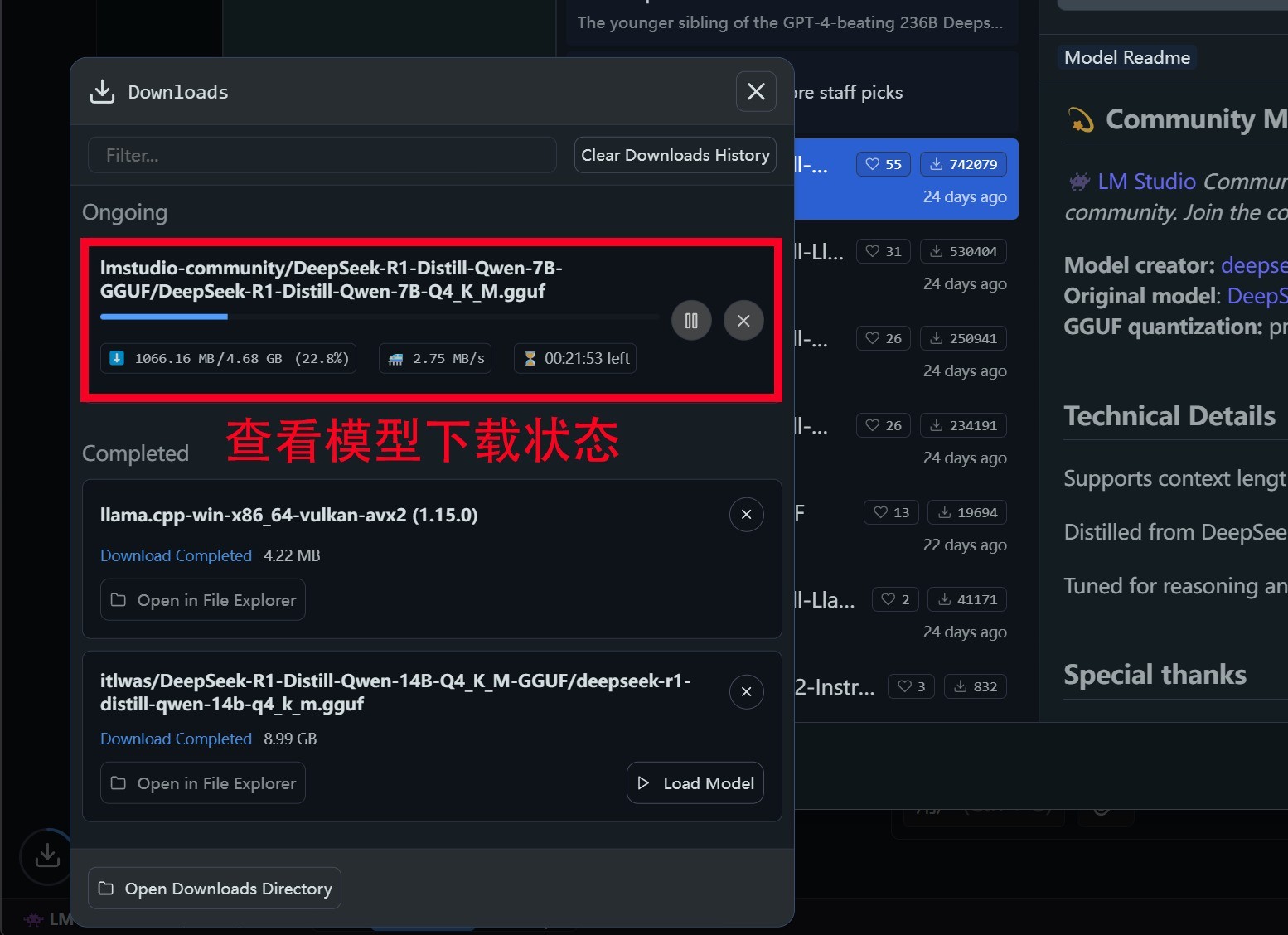
第四步:在搜索栏搜索「DeepSeek R1 Distill」相关的关键词。比如我们要下载「DeepSeek-R1-Distill-Qwen-14B」以及「DeepSeek-R1-Distill-Qwen-7B」两个大模型,直接搜索关键词,并找到对应大模型之后,点击右下角绿色的Download按钮,即可下载相应大模型。同时在弹出的下载界面里可以看到下载进度。此外,AMD官方推荐将所有Distill运行在Q4_K_M量化模式,所以在下载模型时需要从右侧详情栏中确认该模型是否是Q4_K_M量化模式。
「使用」
第一步:大模型下载完成之后是不需要进行任何安装部署操作的,此时我们直接点击主界面黄色的聊天按钮,即可进入聊天界面。
第二步:在正式使用DeepSeek R1 Distill之前,我们需要做的是点击聊天界面正上方的「选择要加载的模型」下拉菜单,此时可以看到刚才下载好的模型名称,同时确保「手动选择模型加载参数」前面的方框处于勾选状态。
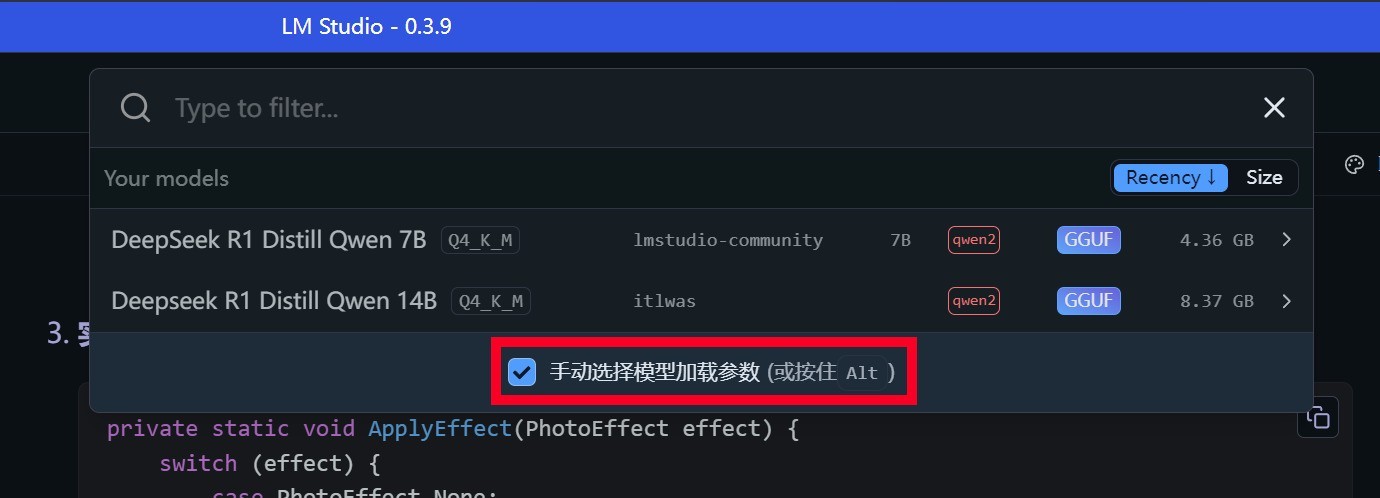
第三步:选择大模型之后会弹出设置菜单,这里我们把「GPU卸载」的条拉到最右侧,其它选项按需设定即可。
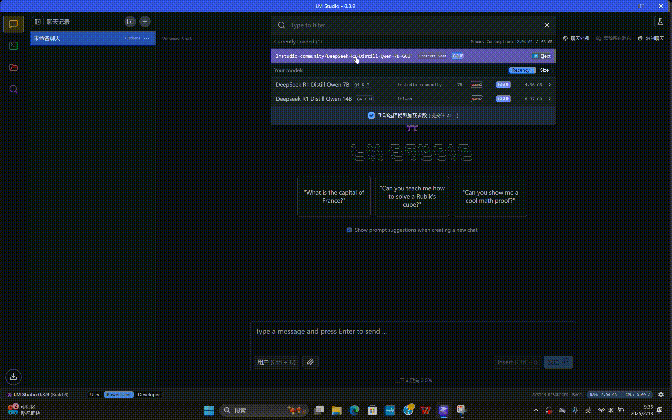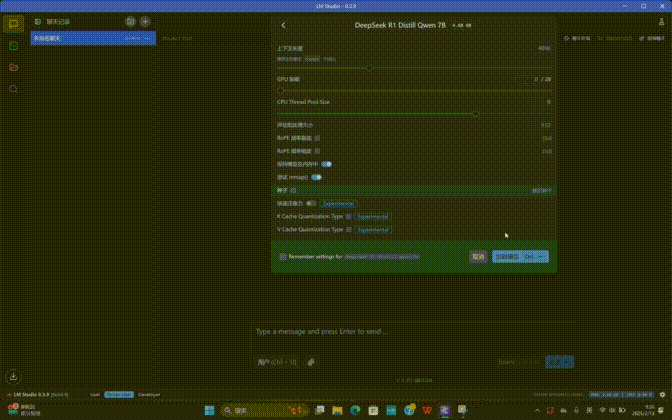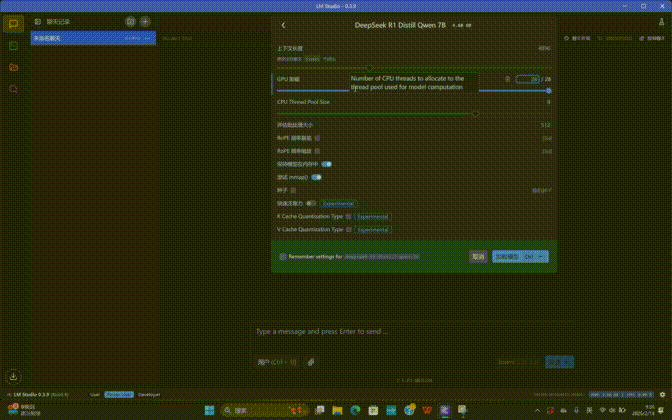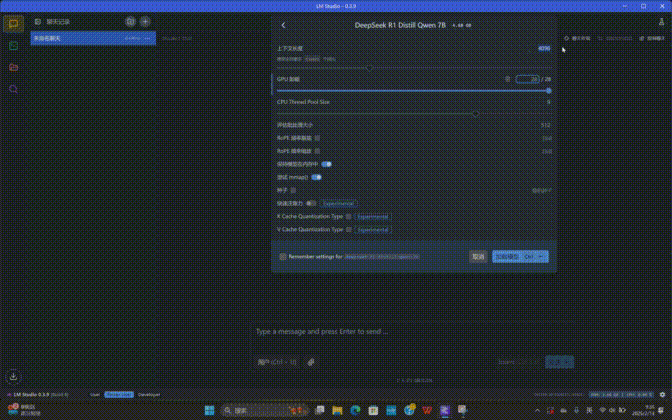
第四步:之后点击右下角的「加载模型」按钮等待模型加载完毕,即可使用DeepSeek R1 Distill大模型了。
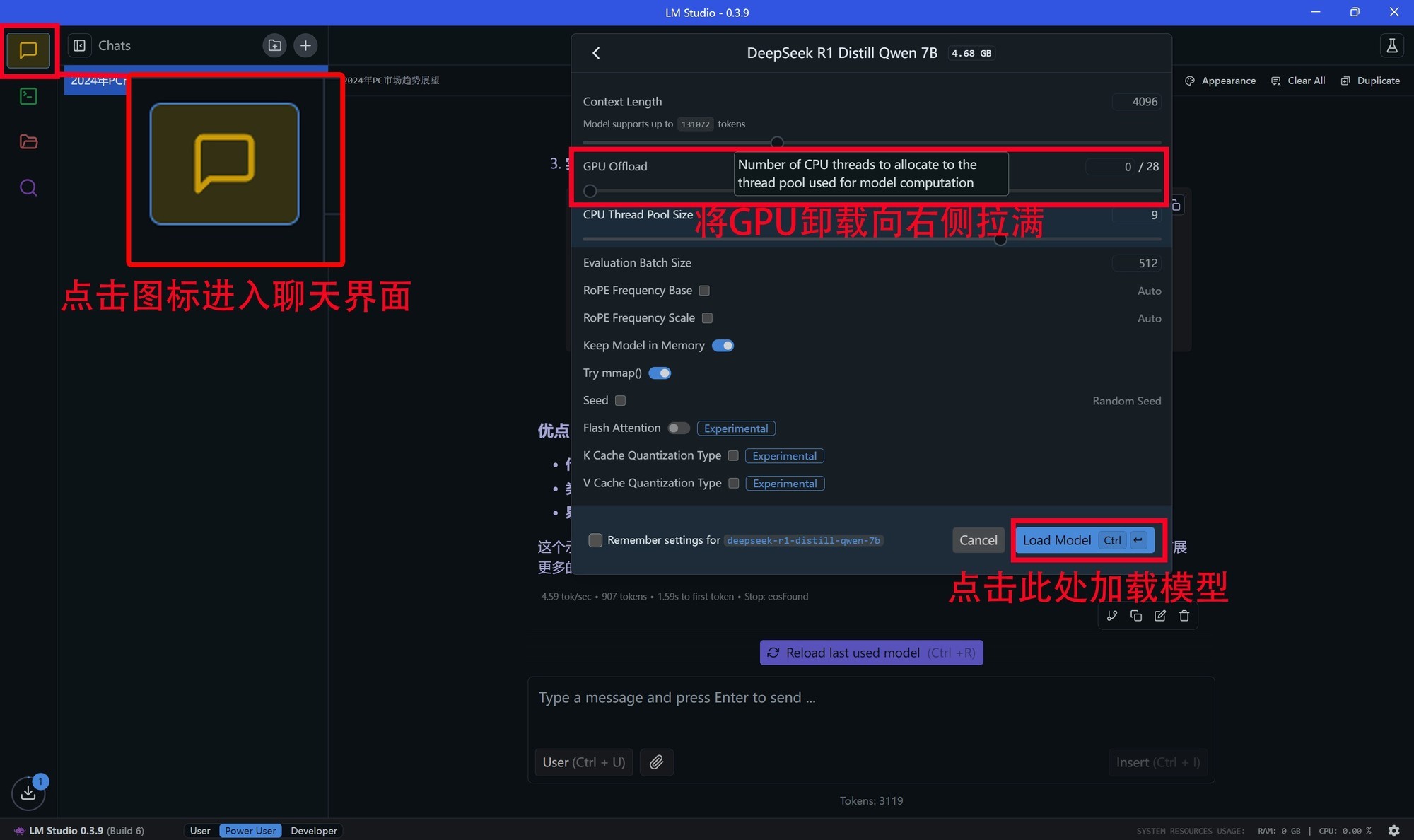
·锐龙AI PC能否顺利运行DeepSeek?
最后我们看看锐龙AI PC能否顺利在本地运行DeepSeek?同时也可以看看它的运行速度到底怎样?
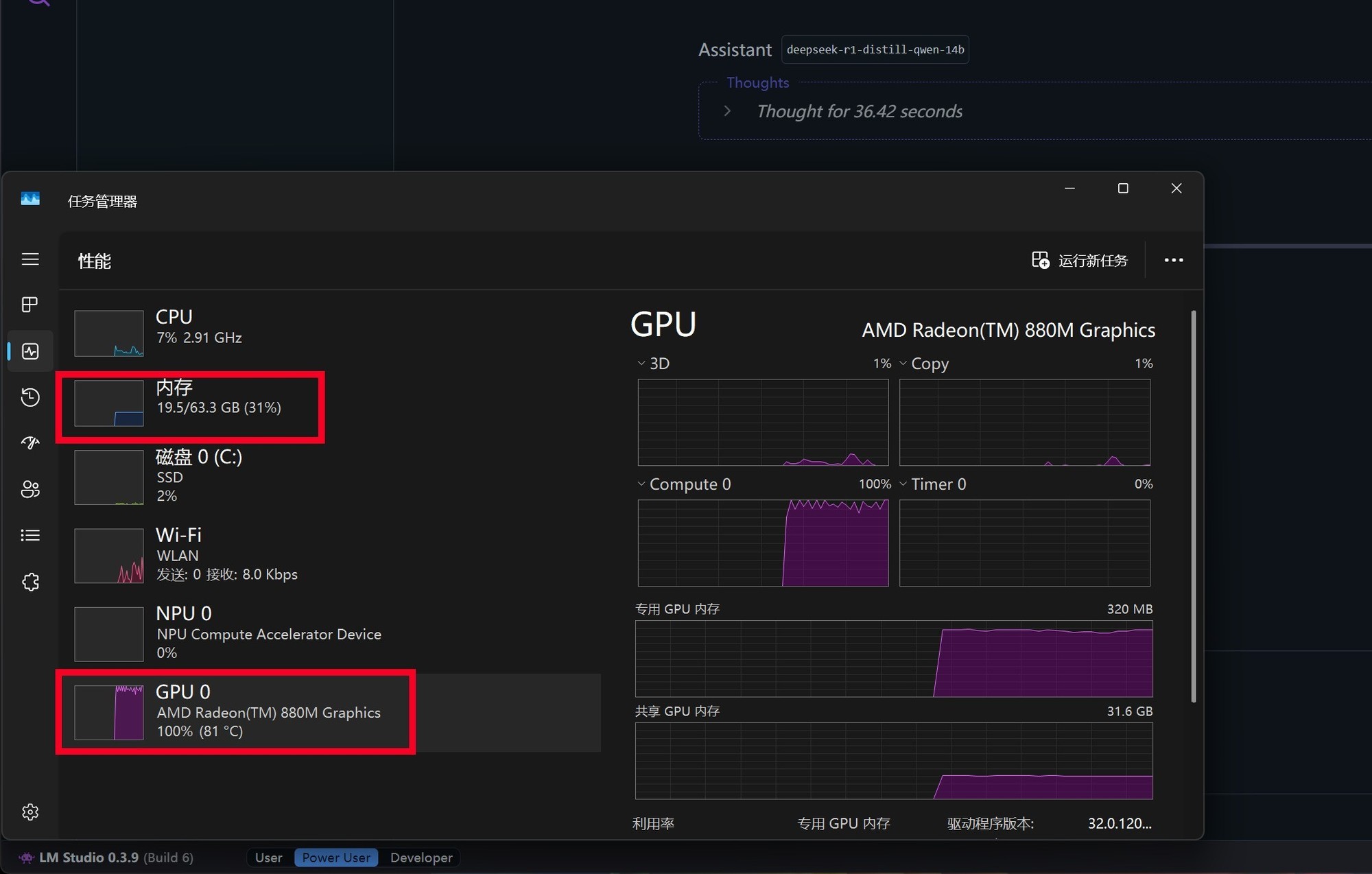
在与DeepSeek进行交互时可以看到,这项应用对GPU资源的占用非常高,几乎达到了100%,同时在内存占用方面会超过20GB,所以普通的8GB、16GB内存运行起来就非常吃力了。另外处理器的占用非常低,一般不到10%。
测试平台所搭载的GPU是AMD Radeon 890M iGPU,运行7B和14B规模的DeepSeek R1 Distill Qwen大模型实测是没有任何问题的,不过速度相比独立显卡自然是会慢上不少。但集成显卡AI PC能够在本地借助硬件算力跑起来14B规模的大模型,这在以往是难以想像的,可见Ryzen AI在算力方面的保障是极为出色的。
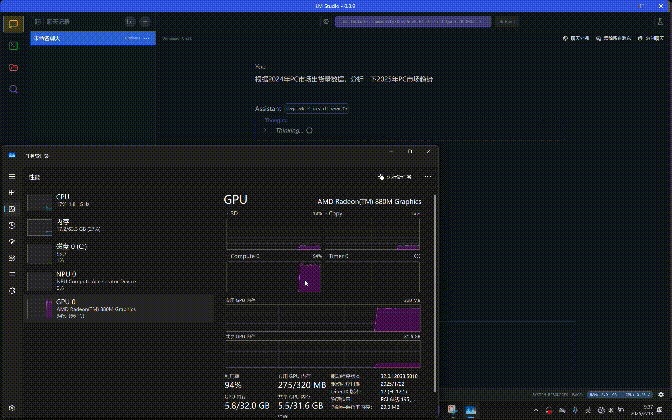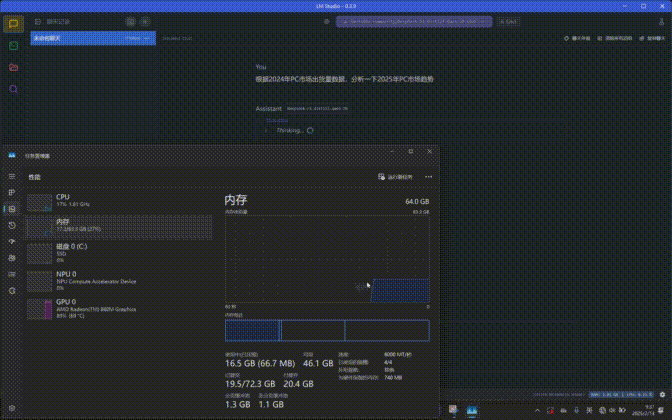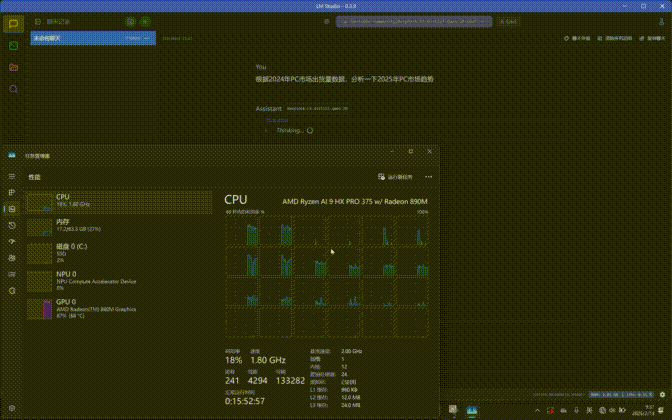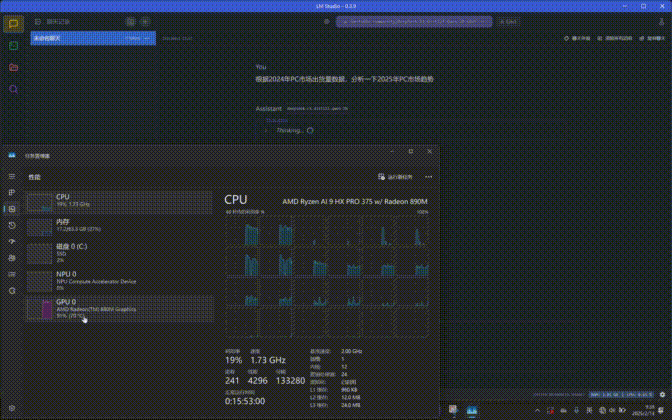
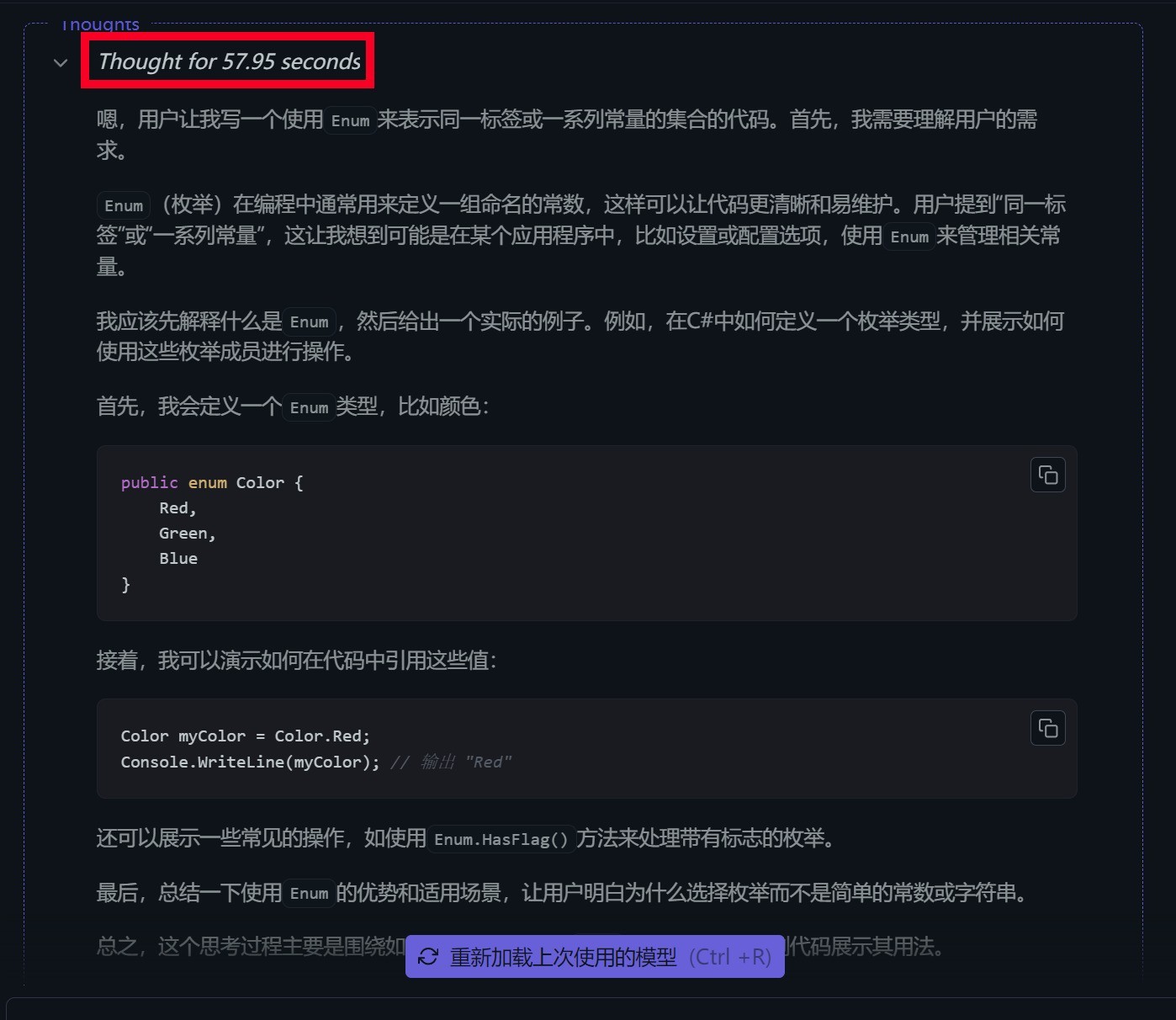
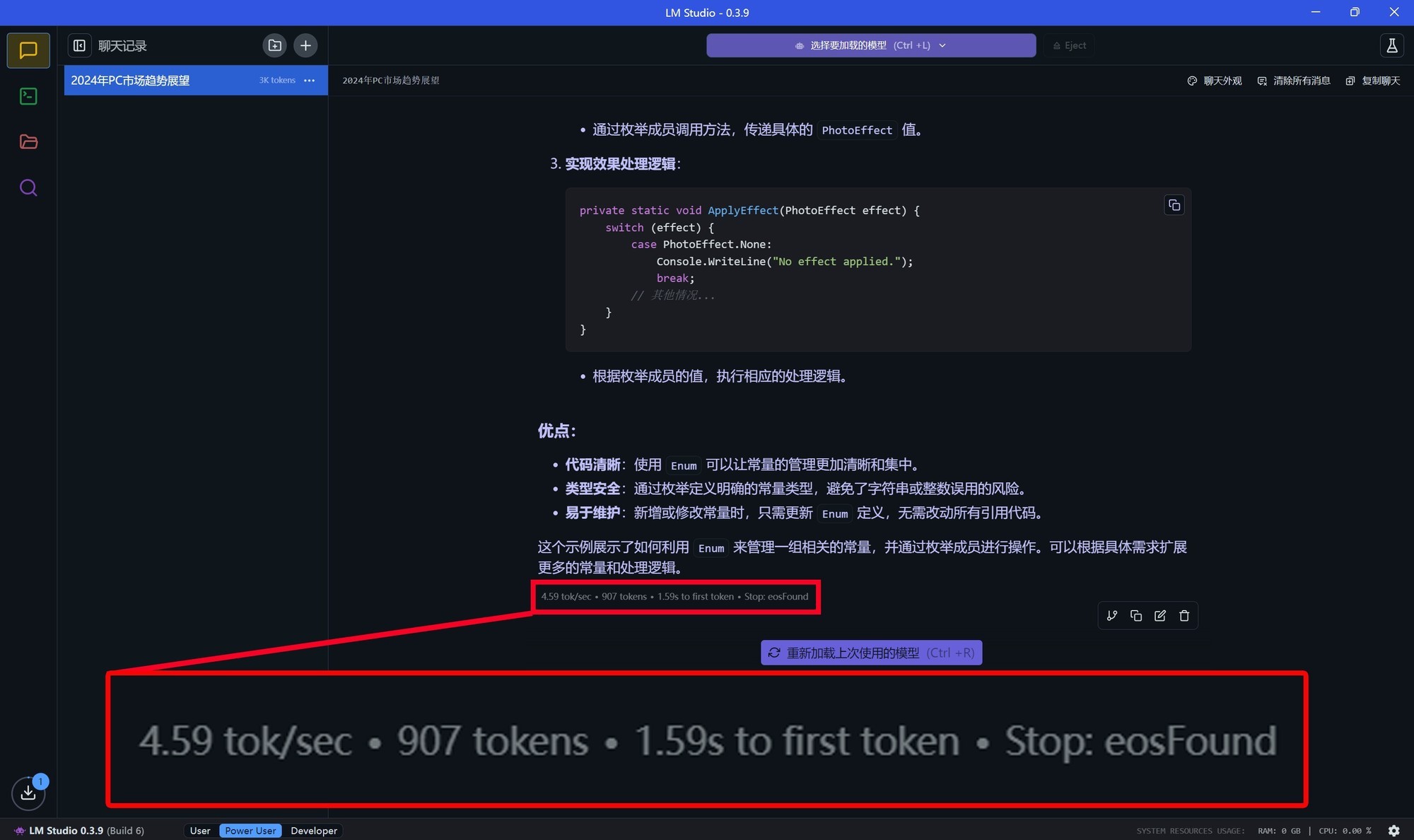
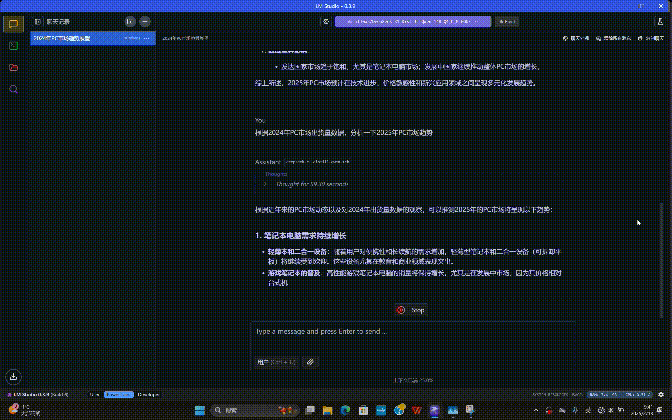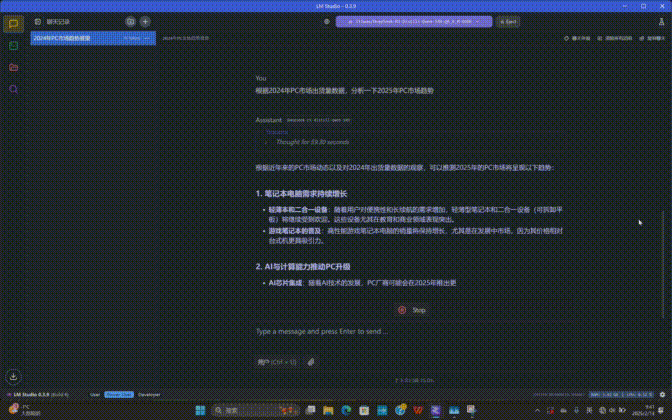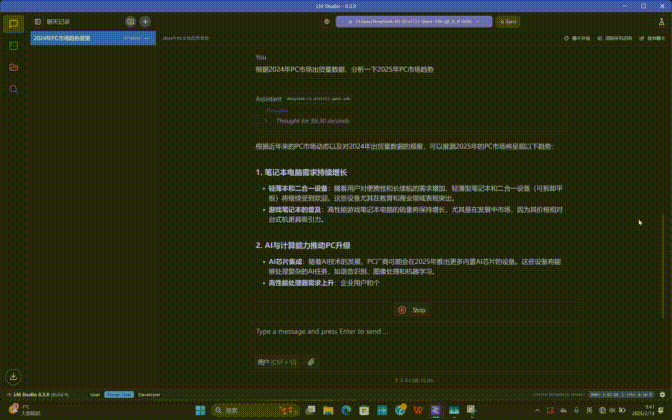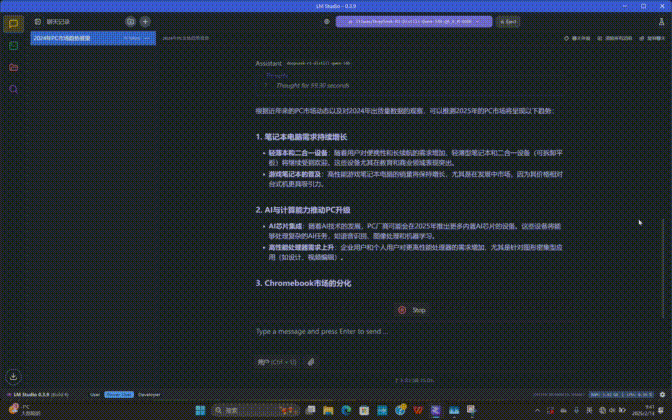
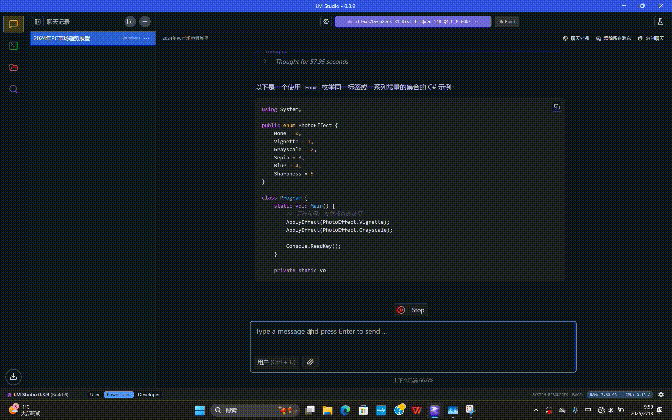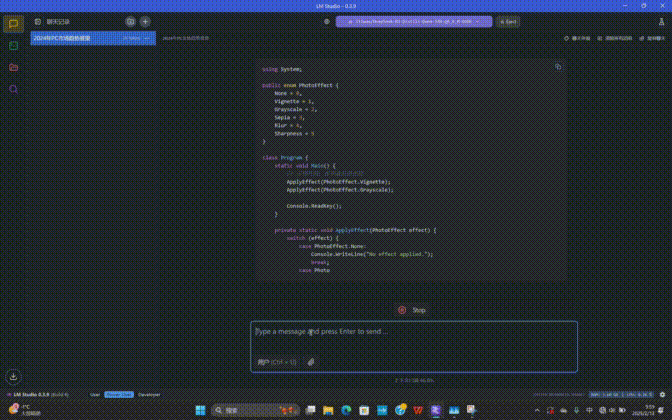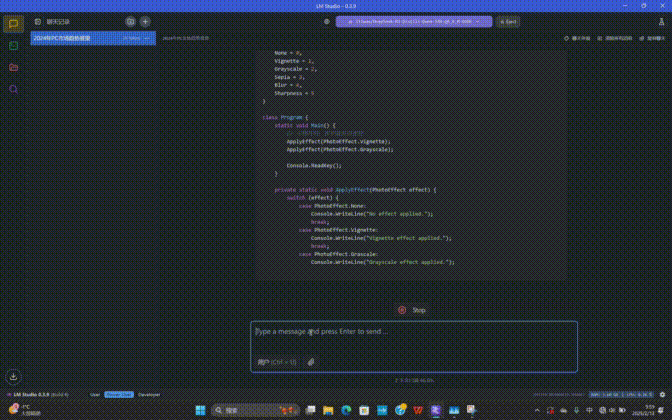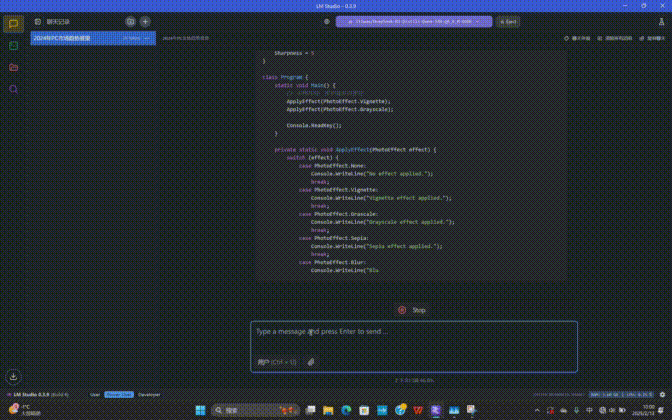
我让DeepSeek帮忙编写了一段“通过Enum枚举同一标签或一系列常量的集合”的代码,使用的大模型是DeepSeek-R1-Distill-Qwen-14B(7B精度相对比较低),前序的思考推理过程耗时为57.95秒,不算快,但考虑到我们使用的锐龙平台只有集成显卡,这个速度以硬件为参照坐标来说,其实已经是相当快了。
在完成整个推理互动过程之后可以看到,首个token生成时间为1.59秒,每秒可生成4.59个token,总计为907tokens。笔者大概看了一下生成的答案,并且请教了程序员同事,DeepSeek给出的答案非常准确。
此外,笔者还尝试让DeepSeek撰写了笔记本产品的评测脚本,分析了2025年PC市场发展趋势等等。整体来说前序思考推理时间基本在45秒-2分钟以内,有着不错的效率。这说明AMD Ryzen AI平台运行本地化的DeepSeek大模型是完全可行,且拥有不错体验的。
·结语
AI PC在经历了一年多的高速发展期之后,所面临的主要问题就是缺少“杀手级”应用,以及用户自主部署本地化AI应用时有着较高的门槛。反倒是在硬件端,其实AMD、NVIDIA这些厂商都已经提供了足够强大的算力支持。
2025开年DeepSeek的爆火,让更多大众用户认识到了当前人工智能是什么、怎么用,基于这一大模型所打造的AI应用,并不需要非常庞大的算力支持。尤其是通过本篇文章中测试就可以看出,AMD锐龙AI 9 HX PRO 375平台在仅有Radeon 890M iGPU的情况下, 就能够在本地顺利且相对流畅地使用DeepSeek-R1-Distill-Qwen-7B/14B这样规模的大模型,足见锐龙AI PC是完全可以满足当前AI应用算力需求的。
此外可能有朋友会问,“为什么要部署本地化的AI?”
这个问题的答案其实用两个核心词就能概括——安全和便利。
本地化AI应用一方面为用户提供了无与伦比的私密性和安全性;另一方面又带来了不错的便利性,它让用户在没有网络的情况下也能够借助AI提升工作、学习效率。此外,相对于目前基本都要付费才能使用的AI应用来说,本地化部署的AI使用成本自然也更低。从AMD官方公布信息可以看到,现在单纯使用非独显的锐龙处理器平台,最高就可以支持到DeepSeek-R1-Distill-Llama-70B超大规模的大模型使用,这真的可以说是“黑科技”了。
本文属于原创文章,如若转载,请注明来源:从部署到使用:一文看懂如何用锐龙AI PC搭建本地化DeepSeek大模型https://nb.zol.com.cn/949/9490672.html