今天咱们聊聊NPU。
大家对于CPU、GPU这些常见计算单元已经比较了解,但是对于NPU却可能并不清楚它的工作原理和具体作用。
NPU即Neural Network Processing Unit,也就是神经网络处理器,从命名就可以看出它是专门应用于AI领域的计算单元。因此相对于CPU、GPU这些通用计算单元而言,NPU理论上是一种无需通用化的特型计算单元,也就是只做好“AI加速”这一件事情就可以了。
虽然目前对于NPU的开发和利用还处于极为初级的阶段,应用方面也只是摄像头背景虚化、降噪等少数一些功能会用到。但实际上NPU自身的计算架构设计特性,决定了它具备比GPU更快的AI计算加速能力。
要理解这一点,首先肯定是要了解NPU究竟是如何从硬件层面对神经网络实现加速的?
Meteor Lake,也就是第一代酷睿Ultra,是英特尔首个集成NPU的处理器。从NPU架构设计可以看到,它的核心是两个神经计算引擎,而核心中的核心是两组MAC阵列(Multiplier and Accumulation)。

我们都知道,AI大模型推理计算简单来说就是在反复做矩阵乘法与加法,其计算结果率先生成预测数据,并通过不断计算让预测数据与真实数据实现最大程度的拟合,以缩小预测数据与真实数据之间的差异,进而最终推理出结果并在用户侧生成所谓的答案。MAC阵列就是为此而生,因此MAC阵列越多,乘法与加法计算的速度就越快,计算速度越快,拟合的过程就会不断提速,最终反映在应用端的就是AI大模型的生成速度加快。
最新的Lunar Lake,也就是第二代酷睿Ultra处理器,NPU中的神经计算引擎增加到了6个,MAC阵列也随之扩充到了6组,理论算力提升3倍。但由于目前大模型推理的主要负载都在GPU上,所以NPU的加速优势暂时无法得到体现。

那么为什么NPU更适合做AI计算加速呢?
我们先来看看GPU是如何做矩阵计算的。
以简单的4×4矩阵乘法为例,矩阵中的每一行每一列的每一个数都要进行16次乘法,所以总计需要进行16×4=64次乘法计算,同时,每一行每一列的每一个数乘完之后都要做一次加法,所以总计算需要进行16×3=48次加法计算。而GPU和NPU计算加速,本质上就是想办法去提升这64次乘法和48次加法计算的速度。
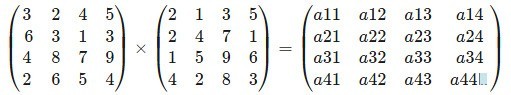
那么GPU与NPU在计算时有何不同呢?
首先GPU最擅长的就是做并行计算。其内部有多个可以同时工作的乘法与加法计算单元。虽然并行计算速度非常快,且能够同时完成多个计算任务,但每一次计算之前,都需要先把数据加载到缓存内,之后GPU控制器会从缓存中把数据取出来放入乘法计算器计算出结果,然后再把结果放回缓存中,之后控制器再把计算结果放入加法计算器中求和,之后再将结果放回缓存,最后再将前面求出的和放到加法计算器中求和,这个结果才是一次乘加计算的最终结果。

举个例子,如果想要计算a11=3×2+2×2+4×1+5×4这个算式,首先需要把这些数读入上图所示意的缓存中,之后读取到乘法器中,分别计算3×2、2×2、4×1以及5×4这四个乘法的结果,再将其结果6、4、4、20四个数放回缓存。我们将这一过程的指令定义为【指令1:乘法】。
之后将6、4、4、20四个数放入加法计算器,求出6+4、4+20的和,并将10和24放回缓存。这一过程的指令为【指令2:加法】。
最后将10和24放入加法计算器,求出10+24的和34,这一过程的指令为【指令3:加法】。
那么如果想要完成4×4矩阵计算,就需要把上述过程再“复制”15次,就可以完成这一矩阵计算任务。也就是说用GPU计算4×4矩阵的话,只需要3条指令即可完成,速度其实已经非常快了。
但从描述中可以看到,想要进行一次简单的4×4乘法与加法矩阵计算,就需要经历:缓存-乘法计算器-缓存-加法计算器-缓存-加法计算器这一系列计算步骤。如果是更大矩阵的计算,那么速度变慢是必然的。比如满血DeepSeek-R1的参数量达到了671B,也就是6710亿参数,想要在如此庞大的数据参数量里做矩阵乘法与加法,硬件性能压力可想而知。
那么有没有比“3条指令”更快的方法呢?
其实聪明的朋友一定发现了,GPU每次计算都要在计算器与缓存器之间将数据来回搬运,如果简化这个步骤,那么速度岂不是就加快了?
没错,NPU的计算架构思路就简化了每次计算都要存取缓存的设计。
如下图所示,NPU的计算阵列利用新建的管道(橙色示意),将乘法器和加法器直接相连,此时乘法器计算完的中间结果就会通过管道直接流入加法器进行加法计算,之后再将结果流入加法器进行最终的加法计算,这样只需要一条指令,即可完成整个乘法到加法的计算过程。

当然,GPU和NPU的计算架构设计并无严格意义上的优劣之分。
GPU是通用计算单元,其计算器设计思路能够满足计算公式的自由构建。
而NPU是专用计算单元,不需要那么高的灵活性,所以人为加入管道之后,只做特定公式计算就可以。
比如,GPU可以做a×b+c×d×e×f或a×b+c×d×e+f等等这样不同的公式计算,但NPU大都只能计算a×b+c×d+e×f这种公式。
当然,英特尔、AMD、苹果设计的NPU可能会有不同的计算器架构,如乘-加-乘或乘-加乘-加乘等等,排列组合方式不同决定了内部数据流动的方式有所差异。另外不同的计算架构设计、不同规模的计算矩阵也会决定其擅长计算哪种数据类型。比如我们常提到的FP16、INT8、INT4等,计算速度就与乘加计算器架构的设计和矩阵规模直接关联。
如下图所示,同样是FP16精度的计算,A100矩阵规模远小于H100,所以后者的计算速度自然就更快。

此外,AI时代的GPU与NPU等计算单元已经与传统意义上的GPU、NPU有所区隔。比如N卡中的TensorCore,实际上就是专用于AI计算的矩阵单元。而某些NPU计算单元除了包含专用于AI计算的矩阵阵列之外,还会融合向量、标量计算单元甚至CPU核心,从而可以更好地满足AI计算时不同的算子需求。
本文属于原创文章,如若转载,请注明来源:为什么NPU比GPU更适合AI加速计算https://nb.zol.com.cn/976/9769370.html