����ʱ��2022��3��30��23������Ӣ�ض���ʽ������ȫ�µ�����Aϵ�и������ƶ��������Կ���Ҳ����Ӣ�ض�����3�Կ����塣��ȥ��Ӣ�ض������Ƴ������Կ��ļƻ��������û�������һ��ĵ����ڴ��Ѿá�
��ʮ������Ӣ�ض�ΪPC�û�������һ����һ��������CPU��Ϊȫ����ʮ�����ṩ�������������ڶ����Կ�����֮ǰ��Ӣ�ض��Ѿ��ڼ����Կ���������˼�ʵ����������������ͼ�μ�������Raja Koduri�ļ��룬Ӣ�ض��������GPU���������Ʋ��ɵ���
Ŀǰ����������Ӣ�ض�����3�����Կ����ʼDZ������Ѿ����У�������ǿ�������5������7ϵ�в�Ʒ���ڽ�������������
Ӣ�ض����Ŷ����Կ�������ͨ�üܹ������ܼ�������֧��DX12 Ultimate�Լ�Ӣ�ض���Ϊ�Ƚ���AI��ý�����档�Ӳ�Ʒ��λ������Ӣ�ض�����3ϵ����Ҫ������Evo�ᱡ�ʼDZ����ԣ�Ϊ���ṩ��ǿ��1080P��Ϸ���ܺͳ�ɫ�����ݴ������ܡ�������5������7���ṩ�������ݴ�������֮�⣬�����ṩ���ߵ�ͼ�μ�����������Ӧ�Ը�������Ϸ����
��ôȫ�µ�Ӣ�ض�����3ϵ���Կ�����Щ�����أ�
��������չ��Xe HPG�ܹ�
���ȣ�Ӣ�ض�����Aϵ�в�Ʒȫ������Xe HPG�ܹ����죬��������ǿ���AI�������ǿ��ý�����档����֮�⣬Ӣ�ض���Ϊ���������һ��Xe��ʾ������µ�ͼ�ι��ߣ������������ֲ�ͬ��ʾ����

Ҫ��ϵͳ�Ե��˽������Կ����ԣ��������ȴ���Ⱦ��Ƭ��Rendering Slice����ʼ̸����Ⱦ��Ƭ��Ӣ�ض�������IP�Ļ��������飬��Xe HPG�ܹ��ÿ4��Xe�ں����һ����Ⱦ��Ƭ��ÿһ��Xe�ں��ж��䱸�������ɹ۵����㵥Ԫ����ʸ������XVE����������XMX������Xe HPGҲ��������������ͼ�μ�������������ɫ�������������ȣ�ͬʱҲ������Ⱦ��Ƭ���ҵ�����Ӧ��Ӳ��֧�֡�

Xe HPG�ܹ�����ص����ӵ�г�ɫ������ԡ���ˣ�Ӣ�ض�����ͨ��������Ⱦ��Ƭ��������ͬ��SoC��Ŀǰ����Ϊ2��������������8���������Ľṹ����Ҫ���ص���ǿ���չ�Ժ�ǿ��������Ⱦ��Ƭ������ͬ����Ʒ�߱�ø��ӷḻ��Ϊ�û��ṩ����ѡ�����ǰ��Xe LP�ܹ���ȣ�Xe HPGÿ������������1.5����ͬʱ����Ⱦ��Ƭ֧��DX12 Ultimate�����а���������ͼ�ι̶����ܿ�ĸĽ������һ���֧����DXR��Vulkan RT��ר��Ӳ������Ԫ��ÿ����Ƭ���䱸��4��Ӳ����������������֧��ʵʱ�����ټ������ܹ���������3A��������Ϸ������ֺ�ӰЧ����


Xe HPG�ĺ�����Xe-Core����Xe�ںˣ�����Xe HPG�ܹ������ģ�飬ȡ���˴�ǰ�����Կ���EU��ִ�е�Ԫ���ĸ�����Xe HPG�ܹ����������ִ�е�Ԫ��Xe-Core��������16��256λ����SIMDʸ�����棬Ϊ��ͳͼ����ɫ��ִ�д����㡣ʸ��������Ҫ����ͳͼ�����ļ�����������AI�㷨���ļ�����ȫΧ����һϵ�д��;���˷����ۼ��㷨��Ӣ�ض���ÿ��Xe�ں��й�����ר�þ�������������Ӳ�����١�Xe�ں˰���16���������棬ÿ�����涼��1024λ������������רΪ����AI���������ͬʱΪ���������ʸ�������ٵ�Ԫ�ĸߴ�������Ӣ�ض���ÿ��Xe�ں��й�����һ��192KB�Ĵ��ͱ����ڴ档�����Ը���ÿ���������ص���Ҫ��L1������������ڴ�(SLM) ֮�䶯̬���䡣
̸��ʸ�����棬Ӣ�ض�Ϊ�˸��������㣨FP���ṩר��ִ�ж˿ڣ���ALU����������Ԫ�������˸Ľ���FPָ�����ڿ�������������(INT)ָ��ͬʱ���У����а���DP4a�Ŀ���INT8���㡣ͬʱӢ�ض���ǿ����AI�������������µ�XMX�����������ڸ�����������˷������������AI�������ͣ�����BF16��INT8��

��ô����������������ģ����ģ��������أ�
���ȣ�MAC��ͼ����ʹ�õĻ���SIMDʸ��ָ��������Կ�ʸ������ĺ��ġ���ִ��8�β�������˷���Ȼ��ִ��8�β��мӷ���ÿ��ʱ���ܹ�16��Ops����DP4a�������Щ����32λ���ȵ�AI�����������Ż������Ĺ���ԭ���ǽ�����32λ����ֳ�8λ�飬Ȼ������ij�����Щ�飬ִ���ܹ�32�β��г˷����ο���ͼ����ɫ������ʾ���� ��������32���ۼӻ�ÿ�������ܹ�64�β�������ȱ�SIMD MAC�����4�����ܡ���������ͨ�����˷��ۼ�4�����ˮ��������������һ���µ�ˮƽ����DP4aһ����ÿ�������������ֳ�4���飬��Щ�鱻��������˺��ۼӡ���ÿ����64������������ɫͼ����ʾ����ͨ��4���Σ�ÿ��ʱ�Ӳ���256�β��������ȴ�ͳ32λSIMD MAC������16�����ܡ�


Ϊ����Ч���ִ�����ܺ�������Ӣ�ض�Xe HPG�ܹ�����ͬʱ���Ⱥ�ִ�и���FP������INT�� XMXָ�����������ʽ�����������������Դ��
��ʵ�����������һ����ҪӦ������ʵʱ��Ⱦ�����е���AI��Ӣ�ض�ʹ�����ּ����ĵ�һ���㷨��ΪXeSS��Ҳ����Ӣ�ض��Լҵij��������������봫ͳ�߷ֱ�����Ⱦ��ȣ�XeSS������Ϸ���ṩ���ߵ����ܡ���ʹ�������縨���˶�ʸ�����ӵͷֱ�����Ⱦ�����ɾ����ĸ߷ֱ���ͼ��

Ŀǰ����һʱ��֧��XeSS����Ϸ�ܼ���14�δ�����»����и�����Ϸʵ�ֶ�XeSS��֧�֡����⣬Ӣ�ض�����Ϸ���������õĹ�ϵ��Ҳ����������ӿ��ٵ���չXeSS֧�֡�

��ǿ���Xeý������ ��֧��AV1������GPU
����ǿ���AI����֮�⣬Ӣ�ض������Կ����ṩ��ǿ���ý�����棬��Xeý�����棬�������������ȵ�ý���������
�����Կ������ص�ý�����������˷dz��㷺�ı�������������H.265/HEVC��H.264/MPEG-4/AVC��VP9�ȣ�ͬʱ������֧��AV1Ӳ���������ٵ�GPU����Ҳʹ�������ݴ��������Ӧ�ñ����ڴ���

���������ص�˵˵AV1��
��Ч�ʱ�������AV1����Ϊ������H.264��������߳�50%����HEVC�߳�20%������ܹ��Ը��ʹ�����С�ļ��ṩ���������Ļ��档����AV1����ȫ����û���κ���Ȩ���õı����������ȻĿǰ��û�б��㷺���ã�����ҵ���û�����ǰ���dz��Ͽɡ�
���������ೣ�õı��������ȣ�AV1�ṩ�˸��õ�ѹ���Ⱥ��Ӿ�Ч��������ͼ���е�AV1����Ӳ�������봫ͳ����ʵ����ȣ������ٶ������50����Ŀǰ������FFMPEG��Handbrake��Adobe��XSplit���Ѽ����˶�����AV1��֧�֡�
��չ�Է��棬Xe��ʾ����֧��HDMI 2.0b��DP1.4a����Ϸ��ҿ�����1080p@360Hz���棬��4̨4K@120Hz HDR��ʾ����չ����Ȼû��֧�ֵ�HDMI 2.1����������չ���Ѿ��ܹ����ǵ��������û�������

���⣬Ӣ�ض������Կ�֧��Adaptive Sync���������ṩ��������˺�ѵ���Ϸ���档���ڴ˻���֮�ϣ�Ӣ�ض���������ȫ�µ�Speed Sync�������������������κ���ʾ���������ͬ���⡣
ʱ�£�������Ϸ��һ�ͨ��V-Sync�Ա����ڸ���Ⱦ��������Ӿ�����Ϸʱ�Ļ���˺�ѡ���������ʾ������Ϸ����ˢ���ʲ�ͬ�����ᵼ���ӳٴ�����ӡ�Speed Syncͨ���ر�V-Sync��������һ�㣬ͨ��ʼ����ʾ���һ����Ⱦ֡�����壬�����������������
���⣬Smooth SyncҲ�ǰ���Ӣ�ض������Կ���һ���¼������ü���ͨ������ģ��������˺��֮֡��ı߽��������Ӿ�ʧ�档

�����ֳߴ������㲻ͬ�ʼDZ���������
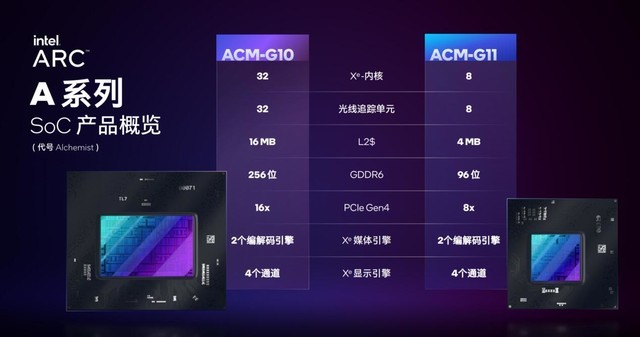
Ӣ�ض�����3�Կ��ֽ���Ҫ������Evo��֤�ᱡ�����������ǵ�������չ����Ӣ�ض���������ֲ�ͬ�ߴ��оƬ������ϴ��оƬ����ΪACM-G10��������32��Xe�ں˺���Ԫ��ӵ��16MB L2���棬256bit GDDR6�ӿڣ�16·PCIe 4.0�ӿڡ������С��оƬ����ΪACM-G11������8��Xe�ں˺���Ԫ��4MB L2���棬96bit�Դ�ӿڣ�8·PCIe 4.0������оƬ��ƾ���������Xe��ܱ�������棬��4·��ʾ������档
GPUƵ���Ƿdz���Ҫ�IJ�����ֱ��Ӱ���������ܱ��֡�Ƶ�������Ӧ�ͻ�Ҫ����ߵĹ�����ѹ����������ġ�Ӣ�ض������Կ�֧��ʵʱ�������ָ�꣬�繦�ġ��¶Ⱥ�ռ���ʣ�����ͨ����̬����ʱ��Ƶ������֮���䡣
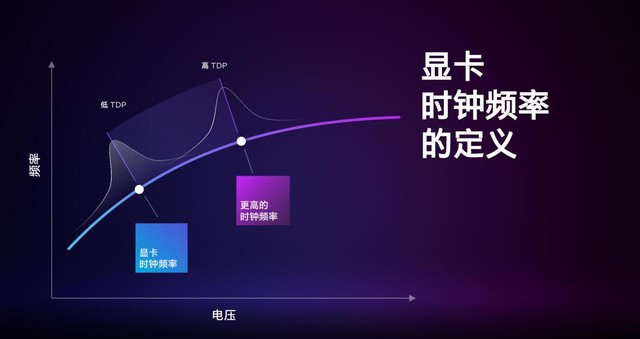
ͨ����˵�ڱʼDZ�����У��������ƻ�ѹ��Ƶ�ʡ�����Կ�ֻ�Ǽ�Ъ�Ա�ռ�ã�����ÿʱ���ڹ����ܶȽϵͣ�ʱ��Ƶ��һ��ͻ�������������֮���Կ����ؽ��أ���������Ϸ��ʱ����ͼ����Ƶ�����ȳ����£�ʱ��Ƶ�ʻ���Ӧ���ͣ������幦�ı�������Ʒ�Χ�ڡ�
��ˣ�Ӣ�ض������Կ������в�ͬ����ʱ������ͬһ���صIJ�ͬ��ʱ����Ƶ�ʡ���ռ���ʵ�ָ���Dz�һ���ģ��Ӷ�ʱ��Ƶ�ʻ���һ����Χ�ڶ�̬���������������Χ�ķֲ�Ҳ���й��ɵģ��ڷֲ��ڣ�һЩ�ӽ��в���Ƶ�ʳ��ֵĸ��ʻ��һЩ��
���ǵ���Щ�����Ӣ�ض��ƶ������Կ�����ʱ�����ȱ궨��һ���д����Եĸ��أ�֮��������������е�ʱ��ȫ�̲�����ͳ��ʱ��Ƶ�ʵķֲ�������������������ɺ�ƽ��ʱ��Ƶ����Ϊ���������еĶ��塣��Ȼ�����ڲ�ͬ��ƽ̨�����Ų�ͬ��TDP��������ɢ�ȵ���ƹ��ġ���ͼ���������ģ������ɵ�TDP�����£�ʱ��Ƶ�ʵķֲ���ΧҲ������������
��Deep Link���������Կ����ܱ���
Ӣ�ض����Ŷ�������һ���������ڳ�ɫ�ĵײ�ܹ���ƣ��Լ��Ƚ���AI��ý������ӳ֡�����һ�������Dz��ò�˵�Ļ�������ϵͳ��Deep Link������

Ӣ�ض�Deep Link����˵���Ƕ��ּ������ܳƣ�Ŀǰ������̬���ʹ�������������ͳ�������������Ҫ������
������ʵ��Ӧ�ù��̵��У�CPU��GPU��������ͬʱ���ڸ߸���״̬���У���˽�����̬���ʹ����������Ϳ�����ϵͳ���ĵ����Ʒ�Χ�ڣ�����������ͷ�CPU��GPU���ܡ�����˵����CPU������Ҫ����ȥ������������ʱ��ϵͳ���Զ��Ѹ���ʷ����CPU����֮��GPUҲһ���������ͽ���˹����˷����⡣
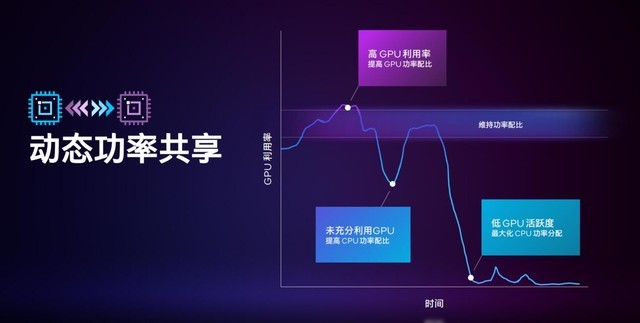
��̬���ʹ�������
��̬���ʹ�������ԭ����ͨ��ѭ���ɼ�����ϵͳ��Ϣ��������������CPU��GPU���¶ȣ�ռ���ʣ����ԵĹ��ĵȵȣ���������ĵIJ������������ʡ���ϵͳ����GPU���ع��ߣ���������Ϸ��ʱ��ϵͳ�ᶯ̬����GPU��CPU�Ĺ�����ȣ�������ʷ����GPU����֮����ʷ����CPU��
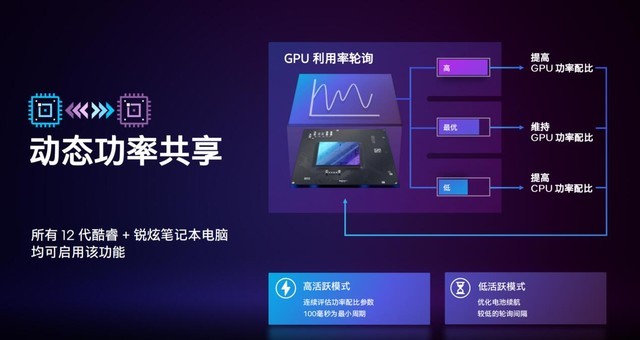
���⣬�Կ�ʹ������ʵ����һ���������䣬��ʱ��Ҫ��GPU�ȡ�����̫��Ҳ����š�����˵��Կ�ռ���ʳ�����һ���䣬�ͻ������Կ�������ȡ����Կ�ռ���ʵ�����һ���䣬������CPU������ȡ������Կ�ռ���ʷdz���ʱ���ͻ�ѹ��ʾ����ܶ������CPU���ֽΣ����д���Ӣ�ض�12����������Կ��ıʼDZ����Զ��ܹ������������
�������뼼��
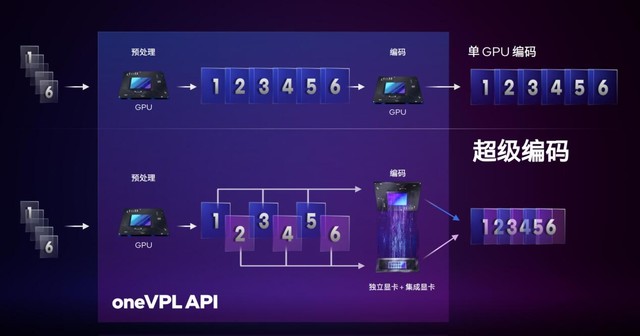
Deep Link��ĵڶ�����Ҫ�������dz������뼼�������������ü����Ĵ��ھ���Ϊ�˴�����������Ч�ʡ����������뼼������ͬʱ�������Ŷ��Ժ������Ե�Ӳ����������������Կ����ǡ��Կ����𡱡�

����Э����ͨ��OneVPL��API�ӿ���ʵ�ֵġ�OneVPL��һ����ƽ̨�Ŀ����Կ�ܣ�Ӧ�ó���ͨ���ӿڿ���ʶ����ƽ̨�϶����ý�����棬���������Ƶ�������������������뿪ʼ����ʱ��һ���������ԭʼ֡ͨ���ض���API����������oneVPL���������鱻���䵽��ͬ�Ķ�ý�������ϣ���������Ӧ���ڴ��л�������������ÿһ���ж���֡����Ӧ�ļ��Ի��߶��ԵĶ�ý������Ὺʼ�����趨�ĸ�ʽ���롣��OneVPL����ɺ����Ĵ���������ѱ�����֡һ����ƴ�ӳ�������Ƶ����������ֲ��д���������Ч�ʱȵ�һ�Կ�����������
������������
�������ݴ������˻����ƼӾ磬��������Ҳ����ߡ���GPU�����������ݴ������Ӧ�����Ч��Ӳ��֮һ����ˣ�������������ij�̶ֳ�����˵����Ϊ���ݴ���������������Ӣ�ض���δ����CPU�����ݴ���Ӧ���еļ���������˳�������������Ҫ��ͨ���Ѹ��غ����ķ������ͬ�������棬�Ӷ�ʵ�ָ��Ӹ�Ч�����ݴ������̡�
Ϊ��Ӣ�ض������MLS�������ڻ���ѧϰ�ķ���
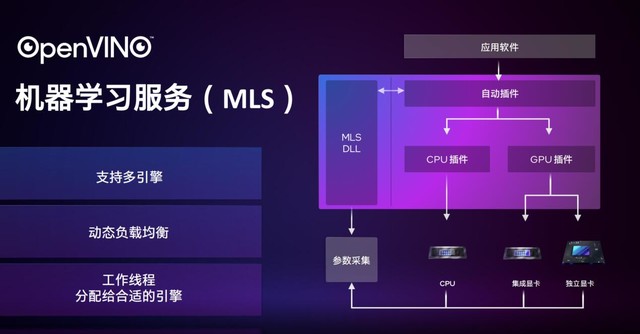
MLS��Open Vino�е�һ����ܣ����ܹ����ܵذѸ��ط������ͬ����ģ�顣���ݵ�ǰӦ�û��������������ӳ����жȣ�������������Ҫ�������ĵȵȡ���Щ���ذ���MLS�������ߣ��Ѹ��ط���������Կ��������Կ�������CPU��
����Ƶ����Ϊ������������MLS�Ĺ���ԭ���������ڶ���Ƶ����ȥ��㣬���֣��ȴ���ʱ�����뻭�����֡���ݸ�MLS��ܣ�ÿһ֡���������ɿ飬��Щ�����ڹ��������MLS����һ���������̣߳�����Щ����������Զ����䵽��ͬ������ģ���С�
����ͼ��ʾ��MLS��һ���ֹ����̷߳��䵽���Եļ������棬һ���ַ��䵽���Եľ������档�����Կ���ɵ�ǰ����MLS����ɷ��µ�����ֱ�����������п�Ĵ����������Щ��ǿ��Ļ�����Ϊ������������
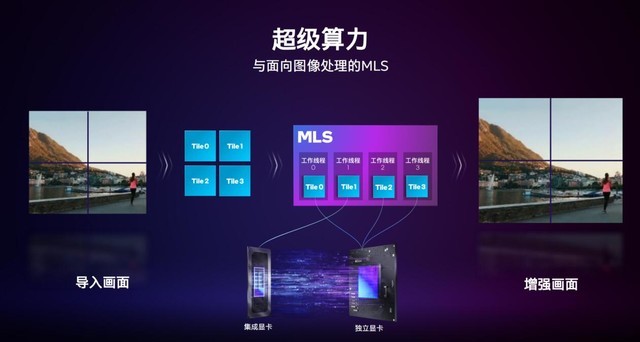
��ʵ������������������ʵ�־��ǿ�CPU������GPU������GPUЭͬ�����������м���ʵ��������Ч�ʵ���ǿ��
������3Ϊ�ᱡ�������ǿ����Ϸ����
�������ع鵽�����Ʒ��Ӣ�ض�������ʽ����������3���壬���ƶ��������Կ�����Ҫ�����ᱡ�ͱʼDZ�������������5������7�Ḳ�ǵ���Ϸ����
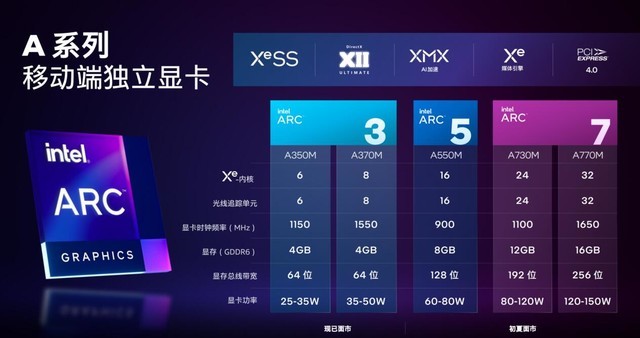
����3�������ͺ�ΪA350M��A370M������У�A350M����6��Xe�ںˣ�6������Ԫ��Ƶ��1150MHz��ӵ��4GB GDDR6�Դ棬64bitλ��������Ϊ25-35W��A370M����8��Xe�ں˺�8������Ԫ��Ƶ��1550MHz��ͬ��ӵ��4GB GDDR6�Դ棬64bitλ��������Ϊ35-50W��

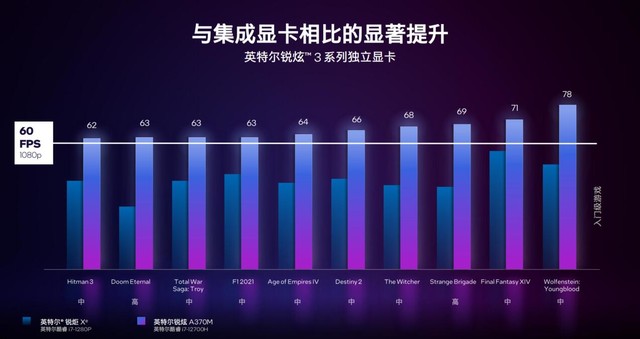
�������Է���ǰ������Ҳ�����ˣ�����3ϵ���Կ���֧��DirectX12 Ultimate������֧�ֹ����٣��ɱ�������ɫ��������ɫ�Ͳ��������������⣬Ӣ�ض�Ҳ�ų���һЩ��Ϸʵ�����ݣ����Կ���A370M������Ӣ�ض����Xe������ȣ�����Ϸ���л�����£�����֡�����컹���൱��ģ�A370M������ֻ����൱�����ġ�
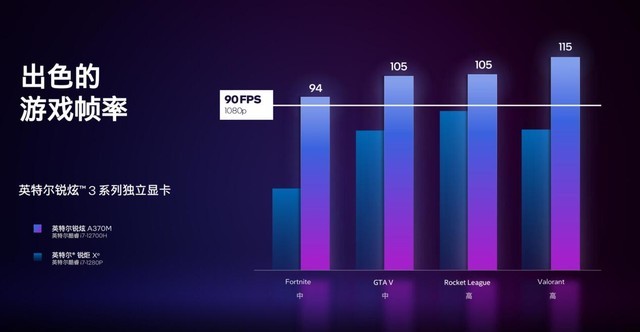
��ʵ�����ᱡ�ͱʼDZ����ԣ��ܹ�����Ϸ�����������ı����Ѿ��൱������
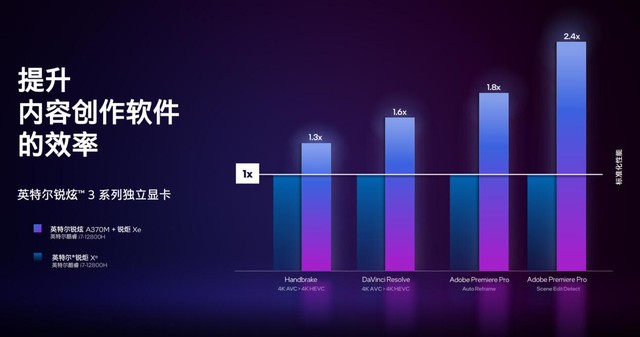
������ĿǰAϵ���Կ�Ӧ��������������������Ը����������ݴ�����������Ƶ����뷽�棬��DavinciΪ����4K H.264תH.265������������Xe�����������60%��
��������3���Է�����Ӣ�ض���������ȫ�µ����ſ�����壬��Intel ARC Control�����ṩ��һվʽ�������Կ���ص��趨������Ϣ���գ������������û�����������������ʱ�����Կ����ܵĹ������ء���������ͷ�趨���Զ�������Ϸ�߹�ʱ�̡��ṩ��ݵ�ֱ����������صĹ��ܺ����ã��û����Կ��ٵĿ���ֱ�����ܽ���Ϸ���ʵĻ��������ֱ��ƽ̨�ϡ�

ARC Control�������Ҳ���ṩ��ݵİ�װ���Զ����·���ÿ��������Ϸ�ϼܻ���Ϸ����������ʱ���û����Զ��յ�֪ͨ������û�����Ҫ����Щ��Ϣ���ţ�Ҳ���Ը����Լ���������������
���⣬ARC Control������廹���ṩ���ܼ��ܣ����Ծ���IJ����Ϳ��ӻ�ͼ���ṩ���û��ο���
Ŀǰ��ARC Control��������Ѿ��������������Ҽ��㲻�������Կ�����Ҳ֧��Ӣ�ض������ԡ�������Ϊ��Ҫ���ǣ�����IJ���Ҫ��¼ʹ�á�
������
����3ϵ�ж����Կ���Ӣ�ض��ع������GPU�����ĵ�һ�Ŵ�������Ƿdz��ڴ��õ�ʵ�ʲ�Ʒ��IJ��Խ��������Ρ�����������������NVIDIA��AMD��ǿ��������ĸ���£�Ӣ�ض��ػ�GPU�г������ɻ���δ�������ڶ��г���ִ�������������ƾ��Ӣ�ض��ļ������������ڲ���֮��Ӣ�ض��Կ�������������ǿ����ʵ����
��������ԭ�����£�����ת�أ���ע����Դ��Ӣ�ض������ƶ��������Կ���������ָ������GPU����http://nb.zol.com.cn/789/7894269.html